Проводите глубокий аудит полей и контейнеров на сайте, например, для мониторинга цен, или извлекайте данные со страниц сайта в любых других целях, сохраняя результаты скрапинга в выгружаемой таблице в формате CSV. Можно даже скачивать изображения и другие файлы. Добавить правило и начать парсинг данных с сайта можно всего за минуту. Все эти возможности доступны каждому, вместе с полностью бесплатным модулем веб-скрейпинга в LinksTamed.
Инструкция содержит полное описание всех необходимых навыков, которые понадобятся для парсинга данных на сайте.
В LinksTamed парсинг сайта возможен не только на статических HTML-страницах, но и на динамических JavaScript AJAX страницах, включая парсинг SPA, PWA (React, Angular, Vue) и прочих веб-приложений, которые вообще могут быть проиндексированы браузерными ботами поисковых систем. Анализируется уже готовое DOM-дерево и прошедший отрисовку (рендеринг) макет страницы, который видит пользователь. Можно извлекать текстовые узлы, например, внутри заголовков H1–H6, фрагменты готового HTML-кода и атрибуты тегов, таких как alt в теге img, а также скачать изображения с сайта на ваше устройство.
Чтобы в процессе скрапинга веб-данных найти контент в конкретном узле (контейнере), нужно создать правило с отличительными признаками этого узла в DOM-дереве (class, id, путь до тега, стили, фрагмент текста и многое другое). Правилу вы присваиваете псевдоним, который станет заголовком в столбце выгрузки в формате CSV или частью пути к скачанному файлу. Это можно сделать всего за несколько кликов в течение минуты. Описание удобного способа добавления правил для скрейпинга веб-сайтов читайте ниже. Там же доступны и более тонкие возможности языка разметки условий.
Где находится в интерфейсе: текстовое поле для ввода правил, кнопка выгрузки в CSV и таблицы со статистикой скрапинга расположены в раскрываемом разделе Фильтры расчетов статического веса, разметка ссылок и извлечение значений на главной странице LinksTamed. Если
Если у Вас возникнут сложности с первыми правилами, можно заказать недорогую услугу по их составлению связавшись с разработчиком.
Разметка и исключение ссылок по признакам в HTML-коде
Назначьте ссылкам псевдонимы по их положению на макете страницы, отделив шаблонные ссылки и ссылки «в подвале». Эффективно оценивайте ссылочный профиль страницы, что особенно удобно при просмотре входящих ссылок и анкоров, а также удаляйте ссылки по псевдониму при расчетах статического веса.
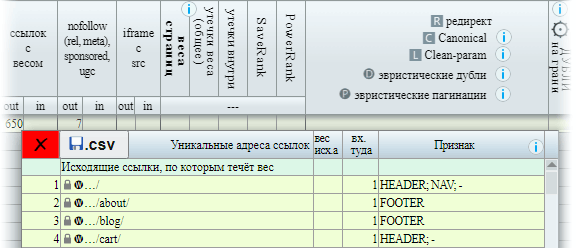
Присвоенные псевдонимы можно будет увидеть в столбце Признак всплывающего окна со списком входящих или исходящих ссылок, а также утечек веса (клик по значению в таблице результатов). Ссылки с присвоенными псевдонимами в этой таблице можно исключать из расчетов и таблиц (здесь и везде зеленый треугольник кликабелен):
▼
На принтскрине изображено окно с деталями на фоне главной таблицы. Первый адрес, который содержит все ссылки с этим идентичным URL, имеет признаки HEADER; NAV; -, это значит, что ссылка встречается три раза: по разу внутри структурных тегов HEADER и NAV, а третья из них не имеет разметки - (прочерк). Наведя на ссылку можно увидеть во всплывающей подсказке анкоры ссылки и сопоставить, какая из них по счету не имеет разметки. Если псевдонимы перечислены через запятую (не более двух), значит эта ссылка отвечает двум этим правилам. Анкоры также доступны при выгрузке в формате .CSV.
Разметка осуществляется за счет поиска в DOM-дереве тега <A> или одного из родительских контейнеров по их отличительным признакам (class, id, путь, стили, фрагмент текста и многое другое), которые указывает пользователь. По умолчанию в поле правил уже указаны наиболее важные секционные теги HTML5: <HEADER>, <ASIDE>, <NAV>, <FOOTER>, однако разметка ссылок за счет специфических для конкретного сайта контейнеров даст максимально детальную картину.
Где находится в интерфейсе: текстовое поле для ввода правил, а также второе, для указания псевдонимов под исключение из таблицы и расчетов, расположены в разделе Фильтры расчетов статического веса, разметка ссылок и извлечение значений на главной странице LinksTamed. При исключении ссылок из расчётов, если несколько ссылок имеют один URL-адрес и не все подпадают под правило - ячейка в столбце Признак будет иметь красный фон, сигнализируя о том, что адрес не был удалён из расчётов.
Базовые навыки для разметки ссылок и элементарный синтаксис языка условий для создания правил и назначения псевдонимов описаны далее.
Добавление правил для парсинга и разметки ссылок за минуту
Чтобы извлечь данные при скрейпинге, а также для разметки ссылок, необходимо указать признаки, по которым краулер будет находить нужные узлы (контейнеры) внутри DOM-дерева. Это делается путем ввода правил в соответствующее текстовое поле на главной странице LinksTamed.
Прежде всего мы должны найти нужный элемент в готовом DOM-дереве. Используем для этого встроенный в браузер набор инструментов разработчика. Вызывать его можно через кнопку F12, a также Сtrl+Shift+C (Windows, Linux, Chrome OS) или Ctrl+Option+C (Mac). Делаем это на странице с типичным шаблоном, для тех, на которых будем делать парсинг. В этой инструкции мы работаем с инструментами разработчика DevTools дизайна Chrome и Chromium. В открывшемся фрейме с инструментами нас интересует вкладка Elements (Элементы) в которой мы увидим уже готовое DOM-дерево.
Теперь мы можем выбрать нужный HTML-элемент страницы. Для этого используем инструмент наведения курсора. Кликаем на значок в левом вернем углу панели, а затем наводим на нужный элемент на странице и кликаем по нему. DOM-дерево на вкладке Elements будет раскрыто и промотано к нужному нам элементу. Кликаем по нужному элементу и вызываем контекстное меню правой кнопкой мыши, где выбираем Copy→Copy XPath.
Теперь, когда мы нашли и скопировали в буфер наше правило (путь до элемента), которое будет искаться на всех индексируемых станицах, копируем путь в текстовое поле на главной странице LinksTamed и добавляем в конец ==#==псевдоним, где псевдоним — это название столбца в выгрузке в формате CSV, а # — метод остановки, который говорит, что на данной странице надо найти этот элемент лишь раз. По умолчанию используется метод извлечения текста innerText. Узнать о других методах извлечения можно в таблице в одном из раздов ниже. Наша строка представляет собой готовое правило, а с новой строки мы можем указать следующее.
Чтобы захватить все однотипные узлы, копируем несколько узлов и смотрим чем различаются их пути XPath, возможно достаточно просто убрать цифру, которая указывает на порядковый номер тега внутри контейнера и после этого сможем получить контент всех узлов подпавших под правило.
Теперь запускаем парсинг, указав адрес главной страницы сайта, краулер самостоятельно обойдет все индексируемые документы указанного поддомена. Мы также можем вставить несколько адресов для парсинга из любых поддоменов или доменов, но в этом случае будет произведен обход только по данному списку. После завершения краулинга и расчетов можно сохранить результаты в формате CSV.
Чтобы запретить обход некоторых областей на сайте, можно добавить свои собственные правила в robots.txt к имеющимся на сайте. Это может значительно ускорить обход сайта. Главное, чтобы краулер мог попасть в нужные разделы при обходе от главной.
Это был короткий пример, который позволяет начать использовать LinksTamed для парсинга данных уже через минуту. Чтобы более детально ознакомиться с возможностями парсинга данных, изучим урок далее:
Изучаем синтаксис на примере в формате мини-урока: Теперь, когда мы узнали из инструкции выше, как работать в DevTools и смотреть элементы DOM-дерева, а также научились копировать готовые правила XPath, мы можем приступить к составлению наших собственных правил на элементарном языке разметки условий DJpath (DOM JavaScript path):
Каждое правило начинается с новой строки и состоит из условий вида тип_условия=значение. Все типы условий не зависят от регистра. Все значения, кроме названия тегов и значения условия TEXT= — зависят. Парсер обходит DOM-дерево сверху вниз, заглядывая на каждый уровень, пока не найдет узел, который отвечает первому условию строки, затем проверяет следующее условие, и если оно последнее и верно, тогда содержимому контейнера назначается псевдоним, который отделен от условий правила ==. Псевдоним служит для разметки ссылок или, при скрапинге веб-сайтов, становится заголовком столбца таблицы в выгрузке в формате .CSV. Таким образом, можно найти узел на любом уровне вложенности, не указывая к нему абсолютный путь от первого уровня DOM-дерева, который может отличаться даже на однотипных страницах.
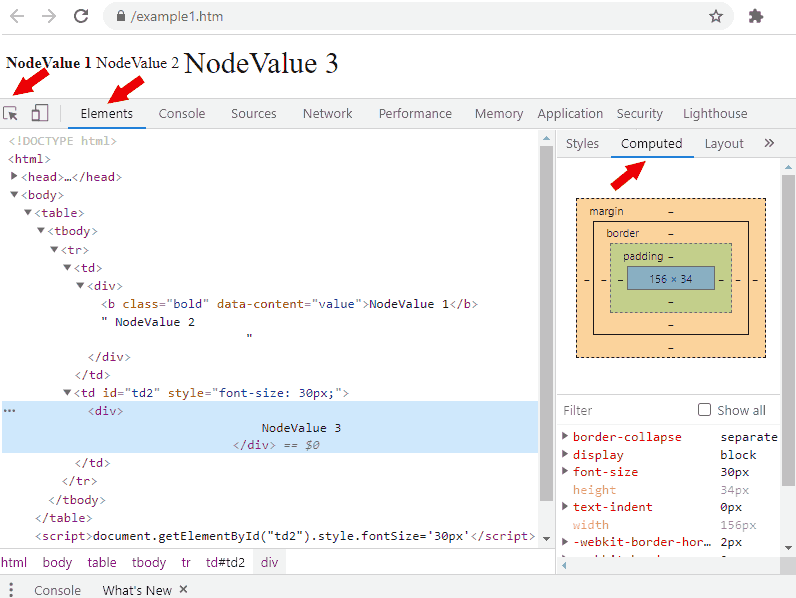
Рассмотрим несколько примеров на основе иллюстрации:
Как видно на иллюстрации, где инструментом наведения курсора был выбран NodeValue 3, вложенными могут быть не только теги <…>, но и текстовые узлы, обрамлённые двойными кавычками "…" (NodeValue 2), если стоят в ряду с тегами. С ними мы тоже сможем работать и извлекать. В конце блоков мы так можем заметить == $0, не обращайте на них внимание.
Из-за особенностей верстки, в конце текстового узла могут быть как пробелы, так и переносы строк, которые будут удалены парсером при извлечении (если они по краям значения) во всех случаях, кроме методов выгрузки HTML кода, о которых рассказано в разделе чуть ниже.
▼
Пример правила: tag=td==псевдоним В этом примере правило сработает для всех ячеек таблицы td. Каждое совпадение, в том числе пустое, будет записано в выгрузке веб-скрейпинга через <.>. При разметке ссылок каждой ссылке в td будет назначена метка в виде псевдонима.
В случае с тегами правило можно записать короче, если тег является стандартным, а не самописным (что допускается в HTML):
Пример: td==псевдоним
Когда одного условия недостаточно, мы можем использовать еще одно условие для этого тега, отделив его от предыдущего условия ;.
Пример: id=td2;td==text td В этом примере мы также проверяем, что ячейка таблицы содержит идентификатор id со значением td2. Обратите внимание, что id=td2 на первом месте, потому что оно более редкое. Всегда ставьте наиболее редкие и не ресурсоёмкие условия ближе к началу (ресурсоёмкость условий раскрывается в таблице-памятке по синтаксису DJpath).
Нажав в DevTools Ctrl+F мы можем узнать, где еще в DOM-дереве страницы находятся элементы с признаками, которые мы выберем, например с таким же class или id. Если class или id уникальны — нам повезло и можно будет ограничиться всего одним условием. Когда мы копируем путь XPath, как было рассказано выше — он всегда уникален. Конечно, мы должны учитывать страницы с похожей версткой, чтобы там это правило не сработало (лучший вариант — указать парсеру с помощью [url=…] на каких страницах следует искать условия). Как бы там ни было, сделать всегда можно сделать выгрузку во время парсинга. Под полем для ввода правил в LinksTamed также есть Таблица проверки корректности извлекаемых данных.
Иногда признаков в самом контейнере недостаточно, тогда можно начать с признаков в родителе (контейнеры оборачивают другие контейнеры и теги, являясь их родителями) и перейти уже непосредственно к целевому блоку с помощью /.
Пример: div/b==text bold Этот пример найдет все теги b на следующем от тега td уровне вложенности. Однако их может быть множество.
Чтобы перейти только к первому тегу используйте tag[n]= Пример: div/tag[1]=b==DIV В этом случае парсер будет анализировать только первый тег (любой), и если это b, тогда условие является истинным. Поскольку мы даем указание искать среди любых тегов, в этом примере нам понадобилось использовать длинную запись tag[1]=, чтобы указать количество для любого тега.
Если мы хотим найти первый тег на уровне вложенности среди тегов именно данного вида, указываем [n] уже для самого тега в коротком виде без tag=:
Пример: div/b[1]==DIV
В некоторых ситуациях первый признак находится значительно выше целевого узла, или количество уровней вложенности от него до целевого сложно подсчитать, тогда используйте //, который означает «где-то там внутри, в том числе и /»
Когда признак не является родителем целевого контейнера, мы можем использовать правило LINKto (но только если этот элемент уже пройден при обходе DOM-дерева, так как документ обходится один раз сверху вниз). Мы составляем отдельное правило и указываем ссылку на его псевдоним с помощью условия LINKto=.
Пример:
title;text=*заг**==псевдоним для ссылки div;LINKto=!псевдоним для ссылки==псевдоним Что тут происходит: сначала парсер ищет заголовок страницы <title>, затем, если условие истинно, для каждого <title> проверяется его текст (TEXT=) на наличие заг. * указывает, что может быть или не быть текст перед заг, а ** что должен быть хотя бы один любой символ в конце, а не просто …заг</title>. ! после LINKto= означает отрицание, то есть мы ищем все теги div на странице, где до этого ещё не сработало это правило.
Обратите внимание, что правило, на которое мы ссылаемся с помощью LINKto=, является самостоятельным. Чтобы это правило было лишь ссылкой и его псевдоним нигде не добавлялся, нужно указать уточняющий метод, перед == — NOTadd.
Пример:
title;text=*заг**==NOTadd==псевдоним для ссылки Обратите внимание на ==…== — это блок уточняющих методов. Наиболее интересные из них # и ##:
# делает сработавшее правило одноразовым, страхуя от повторных срабатываний и добавлений в выгрузку нескольких значений (через <.>)
## делает тоже самое, но при этом останавливает поиск любых правил, причем обоих типов: web scraping и разметки ссылок. Это ускорит анализ страницы, особенно в режиме ускоренный web scraping, когда скрейпинг данных с сайта является единственной целью запуска парсинга.
Пример:
b;@data-content=v**e==#outerHTML==псевдоним В этом примере мы берем значение тега, на котором впервые сработало последнее условие правила. Затем правило удаляется. outerHTML означает, что мы хотим не просто забрать текст по умолчанию, а получить HTML-код фрагмента, включая сам тег (контейнер) на котором сработало последнее условие. Мы также добавили условие @, которое означает, что у тега должен быть атрибут data-content с значением, которое начинается с v, содержит 1 и более символов далее (**) и завершается e. Через @ можно получить id и class, но для удобства мы можем вызывать их напрямую. Метод # говорит парсеру прекратить поиск правил и если включен режим ускоренный web scraping, анализ страницы прекратится ускоренно (продолжится только поиск новых ссылок для очереди на парсинг).
В самых сложных случаях мы можем обратиться к вкладке Computed в DevTools, где можем увидеть вычисленные стили для выделенного элемента, а затем указать один из этих стилей и его значение, как отличительный признак, например мы хотим найти элемент с большим шрифтом, тогда нам нужно свойство font-size, который в нашем примере будет равен 30px для ячейки таблицы с id="td2".
Пример:id=td2;$font-size=30px==псевдоним Это очень ресурсоёмкий метод и его мы будем использовать в самых хитрых случаях и только после всех возможных не ресурсоёмких условий, которые помогут включать эту проверку на как можно меньшем количестве тегов. Об условии этого типа будет ещё рассказанно в описании синтаксиса условий.
В последнем для мини-урока примере зададим правило для извлечения изображения:
img;@src="**dir1/name.jpg"==#@@@DISC==изображение В этом примере парсер будет проверять каждый тег img на наличие у него адреса изображения (атрибут src) необходимого фрагмента. Поскольку адрес содержит служебный /, помещаем значение в двойные кавычки. Для скачивания файлов мы используем метод извлечения @@@DISC, адрес изображения также попадет в выгрузку в столбик изображение. # указывает, что на этом поиск этого правила на странице окончен, что ускорит анализ и избавит от лишних ложных срабатываний.
Это были самые важные базовые навыки синтаксиса языка написания условия, которые позволят без проблем понять и освоить полный набор возможностей в полном описании синтаксиса далее.
Основные моменты при веб-скрапинге и разметке ссылок:
Правила нужно указать до начала парсинга;
Каждое правило начинается с новой строки;
Не более 80 активных строк правил в каждом текстовом поле;
# в начале строки текстового поля позволяет превратить строку в комментарий, а также сделать правило неактивным;
Не все виды условий в правиле могут быть первыми в строке;
Первое условие строки не может быть отрицанием;
Парсер обходит DOM-дерево сверху вниз, проверяя каждый тег на соответствие условиям;
Все названия условий не чувствительны к регистру, пробелы также игнорируются, в значениях условий по разному;
Когда целью парсинга является веб-скрейпинг, можно ограничить разделы сканирования сайта с помощью добавления своих правил robots.txt на главной странице парсера (под кнопкой «Запуск») или запустить парсинг по списку URL-адресов (в этом случае любых доменов);
В обычном режиме возможно спарсить не более 50000 страниц, а в режиме ускоренный web scraping до 100000. В случае использования ОС 32bit или браузера 32bit, или при наличии менее чем 3Gb оперативной памяти, предел следует делить на 2.1.
Подробное описание языка разметки условий DJpath:
DJpath (DOM JavaScript path) - это язык разметки условий для поиска HTML-элементов в DOM-дереве страниц. Работая попутно с основным анализом контента он, в большинстве случаев, находит элементы намного быстрее аналогов. DJpath сочетает в себе множество возможностей, которые оценят SEO-специалисты, при этом его синтаксиc невероятно прост и визуально короток.
Из мини-урока выше мы узнали, как составлять простые правила, что облегчит понимание таблицы, теперь рассмотрим все доступные возможности:
Название
Описание
Условия, которые МОГУТ БЫТЬ ПЕРВЫМИ и последующими в строке правила (TAGname, TAGname[n],tag=, tag[n]=, tag[-n]=, id=, class=)
TAGname,
TAGname[nn],
tag=,
tag[n]=,
tag[-n]=
Позволяют указать название тега, как условие для соблюдения правила.
TAGname позволяет указать название тега без вводного tag=.
Два примера с эквивалентными правилами, в которых проверяется, что контейнер является тегом <nav>:
tag=NAV==псевдоним NAV ==псевдоним
Основные моменты:
Используйте просто TAGname в любом регистре для любых стандартных тегов (есть встроенная проверка валидности). Если это AMP-тег или любой другой самописный, используйте tag= он поддерживает любое название тега состоящее из A-Za-z и - (цифры не поддерживаются);
Слово tag не зависит от регистра букв, все пробелы игнорируются, что удобно для выравнивания;
Группа условий tag= единственная, где также и в значении игнорируется пробелы по краям, а также регистр (который игнорируется ещё только в значении условия TEXT=);
Простое условие tag и TAGname — самые быстрые. Если указать редкий тег и поместить его в начало строки правил, такое правило практически не будет замедлять обход DOM-дерева.
TAGname[n] позволяет указать порядковый номер среди тегов именно этого вида. Отчет идет с 1.
tag[n]= и tag[-n]= позволяют указать порядковый номер тега внутри текущего уровня вложенности DOM-дерева в числе всех прочих тегов (вложенные в теги теги не считаем).
Пример, на котором правило сработает, только если первый тег — это слой <div>:
tag[1]=div==псевдоним
▼
Основные моменты:
Отсчет идет с 1, а отрицательные значения с -1 — это порядковый номер тега с конца;
Если в активных правилах есть прямая и обратная последовательность, лучше выбрать прямую или обратную для всех, так будет чуть быстрее;
[n] и [-n] работает только в сочетании с условием tag или TAGname;
Условие TAGname[n] медленнее tag[n]= и немного замедлит парсинг.
id=, class=
Позволяет проверить, содержит ли тег, который в данный момент проверяется парсером при обходе DOM-дерева, указанный id или, соответственно, class.
Пример: id=x==псевдоним
Основные моменты:
Значение зависит от регистра букв;
Значение может быть в кавычках;
Очень быстро обрабатываются;
По возможности лучше указывать id, так как по стандартам он должен быть уникальным в документе.
Разделители условий (;, /, //)
;
Позволяет указать ещё одно уточняющее условие для данного тега. Пример: A;@href=*dog*==про собак Для улучшения производительности, сначала указывайте наиболее редкое и не ресурсоёмкое правило.
/
Указание искать последующие условия в каждом теге следующего (дочернего) уровня вложенности DOM-дерева. Если необходимо создать абсолютный путь от начального тега DOM-дерева, то им является HTML, хотя лучше от следующего за ним уникального BODY.
Пример, в котором мы получим текстовое содержимое первого слоя <div> в документе на первом уровне вложенности: body/div[0]==псевдоним слоя Если необходимо опуститься на два уровня вниз, нужно сочетать / с каким-либо условием.
//
Указание для поиска вторичного условия на любом дочернем уровне вложенности DOM-дерева. Ресурсоемкость зависит от количества вложенных уровней и кратна /. Следует минимизировать ситуации, при которых срабатывает условие перед этим //, т.е. максимально защитить его от бесполезных срабатываний любым не ресурсоёмким условием.
Пример, с помощью которого будет осуществлен поиск любых выделенных жирным шрифтом слов внутри ячеек таблицы: td//b==выделенное жирным слово Допускается использовать в начале строки //* с целью унификации с путями в языке XPath, в котором такое правило указывает на относительный путь. В DJpath все пути относительные и этот фрагмент просто игнорируется.
Условия, которые могут быть ТОЛЬКО ПОСЛЕДУЮЩИМИ в строке правила (@атрибут_тега, TEXT, $стиль, LINKto, отрицание =!)
@атрибут_тега
Проверяет наличие в указанном атрибуте искомого значения.
Например, проверим наличие у изображения подписи котёнок: img;@alt=котёнок==картинка с котёнком
Основные моменты:
Регистр букв в значении и пробелы (в том числе по краям) учитываются;
Значение может быть в кавычках;
@class= и @id= являются аналогами (для совместимости с XPath путями) class= и id=, поэтому могут быть в первом правиле. Кроме того @атрибут="" может быть обрамлен квадратными скобками [@атрибут=""], которые не оказывают никакого влияния и также служат для совместимости с XPath путями из DevTools (поддерживаются пути Xpath только из DevTools, полный синтаксиc недопустим).
TEXT=
Условие позволяет проверить контейнер на наличие текста из всех его потоков методом textContent.
Например: h1;TEXT=**распродажа новых**==псевдоним
▼
Основные моменты:
Значение не зависит от регистра, пробелы по краям значения учитываются;
Условие ресурсоёмко: следует брать максимально глубокие блоки с как можно меньшим количеством слов, а само условие ставить после более производительных условий, которые отсеят лишние условия;
Слова по краям вложенных контейнеров склеиваются, если там нет пробелов;
"*~| недопустимы как часть пользовательского значения;
Недопустимы как часть пользовательского значения без обрамления в двойные кавычки (="…" или =!"…"): =;/^] и ! (если он первый в пользовательском фрагменте). Используйте * и ** для их замены.
| и звездочки в середине фрагмента являются более ресурсоёмкими, однако после первой такой звездочки в середине, последующие внутри этого значения замедлят не так сильно.
$стиль
Открывает доступ к методу getComputedStyle(), который позволяет проверить, имеет ли контейнер один из более чем 350-ти возможных вычисленных браузером стилей, таких как размеры, цвет текса или фона и тому подобное.
В следующем примере проверяется, имеет ли текст внутри слоя <div> установленную высоту в 17 пикселей tag=div;$font-size=17px==псевдоним Допускается не только точное соответствие =, но и операторы сравнения width=>100 (равно или больше ста (цифра для примера)) и width=<100 (равно или меньше ста, а также если не удалось получить число из значения). Во всех этих случаях будет осуществлена попытка преобразования значения из браузера в число, а %, px и прочее из кода отброшено по правилам метода parseInt(), поэтому в указанном значении должны быть только числа.
▼
Основные моменты:
Условие не может быть первым в строке;
Значение чувствительно к регистру и пробелам, однако пробелы по краям значения игнорируются;
При использовании оператора сравнения = обязательно точное соответствие (включая единицы измерения), а при => и =< в значении должна быть цифра;
Нельзя помещать значения в кавычки, если оно не указанно в кавычках (редкий случай) в панели DevTools (это единственное вид условия, где можно использовать кавычки в пользовательском значении);
В несколько раз более ресурсоёмкое, чем другие условия, при этом дополнительные условия $ для именно текущего исследуемого тега работают очень быстро;
Для стабильного вычисления размеров и стилей необходимо указать на странице настроек адекватное Ожидание AJAX-запросов, асинхронных скриптов и refresh редиректов;
Посмотреть вычисленные стили можно в панели DevTools на вкладке Computed, выделив элемент страницы инструментом наведения из левого верхнего угла панели;
Всегда следует смотреть, какое значение стиля отображает панель DevTools, ввиду того, что очевидное width>0 может не сработать, так как по факту размер может быть вычислен как width=auto;
Размеры в панели DevTools следует смотреть только после настройки ширины окна, с которой будет производиться парсинг и которую можно посмотреть в настройках LinksTamed. Подстроить размер видимой зоны можно при активизации DevTools по всплывающей в верхнем правом углу браузера подсказке, которая активизируется при изменении вами размеров окна. Уменьшить окно получится только до размеров не мобильного бота. Важно понимать, что в стиле записаны не текущие размеры, а вычисленный из различных условий стиль, который может меняться скриптами и такими условиями в CSS как, например, @media.
LINKto=псевдоним
Ссылка, позволяющая проверить, сработало другое правило с псевдонимом, указанным в значении LINKto= в ссылающемся на него правиле.
Детали данного описания связанны с методами извлечения и остановки, описанными ниже в таблице
Пример, в котором мы используем первое правило, как ссылку, при этом даём указание не добавлять поля псевдонима в выгрузку и закончить поиск этих правил после первого совпадения (#):
tag =h1; text=**ноутбук **==NOTadd ==карточка_с_ноутбуком class=artikul;linkto=карточка_с_ноутбуком==#==артикул
▼
Основные моменты:
LINKto — единственный способ задать диапазон — указываем начальный блок (LINKto=псевдоним1) и конечный (LINKto=!псевдоним2), после прохождения которого правило не сможет сработать. Также остановить выполнение исследования можно с помощью последующих правил c ##, в том числе и с ##NOTadd (остановить, но не добавлять);
Условие не может быть первым в строке правила;
Парсер обходит DOM-дерево сверху вниз один раз, поэтому правило с псевдонимом в LINKto= уже должно быть обработано (быть выше по коду), то есть последнее условие правила по ссылке должно быть выше в DOM-дереве тега, где будет проверяться LINKto= на него. Если LINKto= будет в том же месте, где сработало правило на которое он ссылается, работает сложная система приоритетов, описанная в подразделе Отдельные моменты при разметке ссылок;
Псевдоним в самом правиле из LINKto= должен быть уникальным в текстовом поле или быть ==[группой];
Если правило, которое служит ссылкой, не должно приводить к записи значения, следует указать ему вместо == метод ==NOTadd==. ==##NOTadd== служит для остановки исследования правил при обходе парсером DOM-дерева;
Можно сослаться на любой псевдоним, в правиле которого нет ##;
Использовать общий [url=…] только в правиле c псевдонимом из LINKto=, чтобы не упоминать url в каждом правиле, не лучшая идея, так как правила с LINKto попадут на страницу и будут отрабатываться, пока не наткнутся на LINKto=, а не будут удалены при компиляции (перед добавлением), как если бы сами имели собственный [url=…].
=!
Оператор сравнения (вместо простого =), сработает, если условие не отвечает значению.
Пример, в котором записывается анкор ссылки без указанного параметра в самой ссылке (обратите внимание, что подстановочная пара символа ** в середине примера заменяет недоступный в значении =):
tag=a;@href=!**get_param**value**==анкор_ссылки_без_параметра Описание звёздочек читайте ниже в таблице в разделе Подстановочные знаки.
▼
Основные моменты:
Работает для всех типов условий, кроме => и =< в $стиль;
=! не может быть первым условием в строке правила (кроме =!*) из-за рисков снижения производительности;
=! не может быть первым символом в значении пользователя, заменяем его на *, ** или ="!…";
При использовании оператора | может быть только после =, т.е. не найден первый и второй вариант (в комбинации |! восклицательный знак сработает как обычный символ);
Если отрицание сработало — то, чтобы проверить, что атрибут вообще существует, используйте значение =* (точно) — это значит, что атрибут существует с или без значения, а =** (точно) — что еще и не пустое (работают только для ID=, CLASS=, @атрибут_тега=);
Всегда сочетайте =! с утвердительными правилами для избежания замедления обработки и попадания в результаты большого количества ошибочных данных.
Подстановочные знаки
* и **
* вместо одного и более символов в условии class=, id=, @, text=, [url=] означает, что вместо * должно быть ноль и более символов, т.е. может быть или не быть.
** вместо части символов в значении означает, что вместо них должен быть один и более символов.
Например: img;@alt=собака и**==@href==адрес картинки с собакой и другим Помимо обычных комбинаций с текстом могут быть значения, которые состоят только из звёздочек и полезны в сочетании с различными =!:
=* (точно) атрибут существует, включая data="", data= или просто data;
=** (точно) или =!"" означает любое не пустое значение (не нулевая длина);
="" (точно) означает любое пустое значение (data="", data= или просто data);
=!* (точно) проверка, что указанного атрибута нет в данном теге вообще.
▼
Важные моменты:
"*~| недопустимы как часть пользовательского значения, следует заменять их на * или **;
Недопустимы как часть пользовательского значения без обрамления в двойные кавычки (="…" или =!"…"): =;/^] и ! (если он первый в пользовательском фрагменте). Используйте * и ** для их замены.
В TEXT= используйте звёздочки для участков с переносом строк и границ контейнеров без пробелов.
Только такие сочетания могут быть первыми в строке правила: =*, =!*, *x, x*, **x, x** (одно условие с краю);
В первом условии строки, если для условия этого типа все значения без звёздочек или имеют одну длину и положение звездочки, то они обрабатываются быстрее, так как им не нужно по разному обрезать строку.
|
Означает «или», то есть условие отвечает одному из вариантов значения. Доступно только внутри значения (после =).
Пример использования: id=tag;class=class1|class2==class1 или class2 В случае, если используется отрицание =! в сочетании с | внутри значения значит «и», то есть оба варианта должны не соответствовать, таким образом |! — просто восклицательный знак — отрицание может быть только после =.
Специальные условия
[url=…]
Позволяет не добавлять правила на страницы, URL-адрес которых не подпадает под условие.
Например:[url=**botinki**|**tufli;url=!**sandali**]
▼
Основные моменты:
Может содержать *, **, | («или»), а также еще одно условие ;url=,то есть «или» (удобно для отрицаний);
url=! в сочетании с | внутри значения значит «и», т.е. оба варианта должны не соответствовать;
Значение после [url= должно начинаться с *, ** или http, а также отрицания;
Может быть в любом месте строки и будет вырезано как будто его не было, не нужно отделять его /, // или ;;
Значительно ускорит время обработки за счет отключения многосоставных правил, а если правило состоит только из первого условия, ускорит, если не останется активных правил такого вида вообще или хотя бы с таким же положением звездочки для этого вида, в целом, для односоставных правил стоит использовать [url=… только для снижения вероятности ложного срабатывания правил на ненужных страницах.
== ,==псевдоним ,==[псевдоним]
После всех условий и методов == позволяет указать псевдоним, которым будет назван столбец для изымаемых данных или же создана отметка для ссылки (в зависимости от того, в каком из двух текстовых полей вводится правило).
Важные моменты:
Псевдоним не может содержать ; и ";
Даже одинаковые псевдонимы из разных правил записываются в разные столбцы (см. далее, как избежать).
[псевдоним], обрамленный квадратными скобками […], позволяет объединить одинаковые псевдонимы в единую группу, которые будут записываться в один столбик
Важные моменты:
Групповой псевдоним из текстовых полей веб-скрейпинга и разметки ссылок будет раздельным;
При разметке ссылок групповой псевдоним не имеет смысла, кроме как для LINKto, так как одинаковое сочетание отметок для каждой ссылки объединяется в одну.
Методы извлечения и остановки (внутри ==…==)
==…==
== может быть двойным с ==блоком методов==псевдоним, где перечислены особые указания для изъятия данных и остановки парсинга данных, которые перечислены ниже в данном разделе таблицы.
В текстовом поле разметки ссылок поддерживаются только ==, ==#==, ==##==, ==NOTadd==, ==#NOTadd==, ==##NOTadd==, ==ignore==, ==#ignore==, ==nottext==, ==#nottext==, остальное касается только скрейпинга
==innerText== или просто == (по умолчанию)
Указание использовать свойство innerText в качестве метода получения контента. Значение будет получено, как если бы пользователь выделил и скопировал этот участок текста. Идеально подходит для многостраничных значений: скрытый с помощью display:none контент, а также содержимое тегов <script> и <style> игнорируется, однако содержимое owerflow:hidden будет скопировано, т.к. на самом деле остается в макете страницы. Блочные теги создают переносы строк, сохраняя абзацы;
==textContent==
Чуть более производительный метод textContent для простых значений без переносов строк. Содержит весь текст скрытых слоев и текст таких тегов как <script> и <style>. Блочные элементы не переносят строк и не создают пробелов — слова без пробелов между блоками будут склеены (TEXT= использует такой же метод).
==innerHTML== и ==outerHTML==
==innerHTML== позволит получить HTML-код внутри контейнера с переносами строк.
==outerHTML== позволит получить HTML-код, включая сам контейнер, например, не только анкор, но и саму ссылку. Аналог ==^innerHTML== (о ^ ниже в таблице).
▼
Важные моменты для восстановления фрагментов HTML-кода:
Все двойные кавычки " в полученных данных будут удвоены ("") и при открытии в Excel, OpenOffice и тому подобном софте будут отображаться нормально. Таково требование экранирования символов в формате .CSV. При этом, при копировании в буфер обмена, значения снова будут содержать пары двойных кавычек;
При распарсинге следует учитывать, что значения, содержащие переносы строк, уже удвоенные двойные кавычки"" и ;, а также значения, которые были найдены, но оказались пустыми и не содержат символов, будут обрамлены в двойные кавычки.
группа указаний nodeValue
Позволяет получить текстовые узлы первого уровня вложенности (без содержимого вложенных контейнеров):
==nodeValue== получить все текстовые узлы первого уровня, т.е не вложенные в теги (каждый текстовый узел будет отделен <,>);
==nodeValueFIRST== и ==nodeValueLAST== — получить только первый или, соответственно, последний текстовый узел контейнера.
@атрибут_тега
Указывает получить значение указанного атрибута элемента. Регистр букв названия игнорируется. При получении значения, если оно ссылка, будет получено начальное значение, т.е. путь не будет приведен к абсолютному, если в HTML-коде указан как относительный (без домена).
@@@DISC и @@@DISC[…,…]
Позволяет сохранять изображения и другие файлы на жесткий диск. Работает автоматически с тегом IMG, где берет ссылку в атрибуте SRC или в атрибуте HREF тега А. Во втором случае возможно закачать и другие файлы (включая статические версии HTML-файлов), но в этом случае нет гарантии беспроблемного парсинга:
Диалоговые окна «Сохранить как»: вероятность появления и предотвращение его появления
Перед первым использованием метода в браузере, необходимо убедиться, что в настройках этого браузера в разделе Настройки>Дополнительно>Скачанные файлы отключена опция «Всегда указывать место для скачивания», иначе для каждого сохраненного файла будет открываться диалоговое окно для указания места сохранения;
В браузере есть понятие «небезопасные файлы», попытка их загрузки приведет к блокировке загрузки или появлению диалогового окна сохранения для каждой такой загрузки. К ним, если верить заявлениям, может относиться в будущем изображение в формате PNG. В среднесрочной перспективе не гарантируется получение файлов без диалогового окна (без более глубоких настроек безопасности браузера) по незащищенному протоколу http:// и со смешанным содержимым (страница https://, файл на http://). Подробнее об ограничениях читайте в блоге разработчиков Chromium. Разрешить загрузку блокируемых и небезопасных файлов можно перенастройкой опций безопасности браузера (информацию об этом и о рисках ищите в поисковых системах). В любом случае, сначала стоит попоробывать сделать парсинг, так как есть большая вероятность, что проблема этого типа вас не коснется, особенно если вы качаете изображения;
В случае появления диалоговых окон, будет открыто окон, равное по количеству потокам в настройках (иногда пользователь может щелкнуть по вкладке в момент появления такого окна, и оно будет скрыто на заднем плане). В случае приостановки парсинга, а также остановки или изменения настроек для их подавления, нужно прокликать количество равное потокам. Если нажать на отмену, файл будет добавлен в очередь снова указанное на странице настроек количество переобходов при ошибках;
При загрузке файлов, которые представляют из себя HTML-страницы, могут возникнуть не ситуации с невыявленной закономерностью, когда для файла не будет правильно выбрана папка и содержимое будет загружено в папку последнего файла не в виде документа, что является багом браузера.
Файлы сохраняются в папке Загрузки(Downloads)/LinksTamed/WebScraping/домен_проекта*/псевдоним/_NOT_GOOD_**/протокол_и_домен_файла/путь/имя Примечания: *домен_проекта при мультидоменном краулинге по строгому списку всегда один - 1-го адреса в списке.
**/_NOT_GOOD_/ — эта подпапка появится, если на странице есть любая каноническая рекомендация canonical не на себя (работоспособность не проверяется на момент скачивания) или noindex без nofollow. Контент страницы с noindex, nofollow (none) или Disallow не обрабатывается вообще на данный момент, следуя правилам для поисковых ботов. Clean-param обрабатывается после парсинга и не может быть учтен. В выгрузке скрейпинга все эти директивы и рекомендации будут отмечены уже в обработанном виде и некоторые могут отсутствовать из-за того, что признаны ошибочными (при этом останутся в _NOT_GOOD_). Разделение необходимо, чтобы не засорять результаты поиска похожих изображений в стороннем софте. Содержимое /_NOT_GOOD_/ может быть объединено с файлами основного пути простым перемещением содержимого.
Для возможности сохранения в различных файловых системах, перечисленные далее символы будут закодированы по следующим правилам:
Следующие символы и их последовательности, которые недопустимы в файловой системе и не были закодированы самим браузером, будут заменены на HTML-мнемоники:
Исходный символ
HTML-мнемоник
?
?
*
*
:
:
|
|
://
://
/ в конце URL
/
// (2 и более) после домена
//(новая папка)
Имена и каталоги, длина которых с мнемониками превышает 127 символов, будут обрезаны до 126 символов с многоточием (…) в конце (HTML-мнемоник в конце также может быть частично обрезан).
Адрес также будет добавлен в выгрузку скрейпинга в столбец с соответствующим псевдонимом, при этом будет указан абсолютный путь (т.е. будет включать протокол и домен), даже если в исходном коде он был относительным. Длина ссылки учитывается при расчете длин извлеченных значений в таблице наблюдения за ходом скрейпинга, так что не удивляйтесь значениям. В выгрузке можно посмотреть к каким страницам относятся загруженные файлы (эти файлы не отображаются в общей статистике, но в случае невозможности сохранения — будут отмечены в аудите, но не более 2000 ошибок).
Картинки будут растасованы в папки по псевдонимам. Таким образом, можно искать с помощью стороннего софта похожие изображения в одном месте шаблона (за счет того, что результаты не будут засорены превьюшками из каталогов и картинками в ссылках Cross-sell (Кросс-сейл) и Up-sell (аппсейл) в карточках на другие товары). Найти изображения с одинаковым адресом на разных страницах можно с помощью стандартных функций Excel.
▼
Важные моменты:
Файлы с закрытых от индексации страниц (robots.txt disallow, meta или X-Robots-Tag noindex,nofollow и none) не будут скачаны;
Если сайт пересканируется, все изображения с теми же путями будут перезаписаны, но останутся старые, поэтому удаляйте, переименовывайте или перемещайте папку с файлами до следующего парсинга;
Если изображение будет отвечать нескольким псевдонимам, оно будет загружено в каждую из этих подпапок;
Файлы, которые не были загружены из-за проблем, отображаются в аудите, а не в выгрузке результатов скрейпинга;
C помощью стандартного поиска в вашей ОС, можно искать атрибуты в нужных папках;
При загрузке файлов появится панель загрузки в нижней части браузера, если для вас это проблема то, чтобы скрыть её, используйте сторонние расширения, такие как Hide Download Bar или Disable Download Bar;
Чтобы недопустить присвоение одного псевдонима картинкам в разных местах в макете страницы, используйте #;
Метод не работает с ftp каталогами;
При загрузке может произойти редирект, однако в папке и выгрузке будет указан первичный путь из HTML-кода;
Если файл будет найден по другому правилу с другим псевдонимом, файл будет закачиваться еще раз;
Дубликаты изображений с тем же адресом можно посмотреть в самой выгрузке;
Проверьте, что свободно в несколько раз больше от необходимого (по прикидкам) места на жестком диске, так как базам данных LinksTamed тоже нужно место и с запасом.
@@@DISC[…,…]. Иногда может понадобиться заменить фрагмент адреса на другой, например, чтобы загрузить не превью, а полную картинку, адрес которой недоступен в DOM-дереве (например, на сайте есть изображения в теге img с альтернативными разрешениями в атрибуте srcset, при этом указанное по умолчанию в атрибуте src изображение не того разрешения, которое нужно). Используйте для этого после @@@DISC выражение [заменяемый_фрагмент,вставляемый_фрагмент] или [заменяемый_фрагмент,] для удаления фрагмента. Допускаются несколько выражений для замены @@@DISC[…,…][…,…]. Одно правило срабатывает один раз и его нужно повторить для замены в нескольких местах адреса идентичных фрагментов. Адрес меняется и в выгрузке.
# и ##
# делает правило одноразовым. Это означает, что правило сработает только один раз на каждой странице и далее больше не будет искаться в этом документе. Защищает от ложных повторных срабатываний и улучшает производительность, особенно когда первые условия правила часто срабатывают и когда в правиле есть / или //.
Чтобы остановить поиск условий вообще, укажите метод остановки ==##==псевдоним для последнего по коду правила, которое точно или высоковероятно будет найдено. В этом случае остановится анализ правил из обоих текстовых полей. Если это затруднительно или нет правила, которое с гарантией будет присутствовать на странице, но есть другие опорные элементы (которые подойдут под простое правило), используйте остановочное правило с указанием ==##== БЕЗ псевдонима. Указать такое правило особенно важно в случаях, когда есть правила без указания [url=…], которые будут искаться на всех страницах, включая и те, где они быть не могут, в этом случае пометьте контейнер типичный для большинства шаблонов, который находится после собираемых на других страницах данных. После срабатывания остановочного правила, поиск полей будет отключен и продолжен обычный парсинг, а в режиме ускоренный web scraping — обход продолжится ускоренно и лишь для поиска новых ссылок.
▼
Важные моменты:
Может # и ## могут сочетаться с любыми методами извлечения, быть перед или после них внутри ==…==;
Если для тега срабатывает ## и другое правило, оно может успеть сработать до остановки согласно приоритетам, описанным в подразделе Отдельные моменты при разметке ссылок;
При указании правил в текстовом поле разметки ссылок, если # и ## применено к контейнеру, все ссылки внутри него будут размечены, а уже следующий будет проигнорирован, поэтому к практически каждому контейнеру можно применять # или ##;
## единственное, что едино для текстовых полей разметки ссылок и веб-скрейпинга, поэтому приведет к остановке исследования правил из обоих текстовых полей;
При выборе опционального режима ускоренный web scraping важно убедиться, что обход может остановиться, для этого лучше использовать ## в правиле, которое должно сработать на блоке ниже остальных в исходном коде;
Если для страницы правильно и четко указаны правила, все содержат метод остановки # и все будут найдены — поиск правил остановится, однако если будут лишние или отсутствовать желаемые, обход будет продолжаться в холостую.
^ или ^[n]
Позволяет подняться на указанное кол-во уровней выше по DOM-дереву и получить контент с учетом родителей: ^ или ^[1] — на один уровень; ^[n] на указанное количество уровней. Для парсинга всего HTML-документа используйте большое число — будет взят контент последнего (первого) существующего контейнера — HTML. Может быть в любом месте внутри ==…== и сочетаться с другими методами.
==NOTadd==
Позволяет не добавлять правило. Чтобы остановить исследование правил, используйте правило с ==##NOTadd== без псевдонима в конце, который имеет смысл использовать только для визуализации в инструменте тестирования. Про другие варианты использования как ссылки в других правилах, в том числе как задать диапазон, читайте в описании к условию LINKto=.
==ignore==
Позволяет полностью игнорировать блоки макета (включая ссылки) при всех видах сбора данных, в том числе и при обычном парсинге, как будто их нет вообще. Основное назначение - сделать алгоритм поиска частичных дубликатов страниц более чувствительным и ускорить его за счет исключения областей документа с, например, подгружамемыми к основному материалу статьи другими статьями или просто шаблонными блоками. Стоит учитывать, что если краулер работает не по списку и самостоятельно обходит страницы, он может не попасть на какие-то страницы, так как игнорируемых ссылок для него не существует. Это правило можно вписать в текстовое поле ввода правил скрейпинга или разметки ссылок.
▼
Важные моменты:
Если метод затронет первый заголовок <h1>, это скажется на его отображении в главной таблице с данными (может быть показан и последующий незатронутый методом H1, если их несколько) и может повлиять на оценку дубликатов (так как он имеет повышенное влияние). Также возможно сообщение в аудите о пустом H1;
Допустим только чистый метод ==ignore== и сочетание ==#ignore==;
Метод не окажет влияние на заголовок <title> страницы и meta description;
Нельзя управлять индексацией: заставить игнорировать canonical, noindex и none.
Если для одного и того же тега срабатывает ignore и другое правило (это, в основном, касается извлечения данных), оно может успеть сработать до включения игнорирования согласно приоритетам, описанным в подразделе Отдельные моменты при разметке ссылок;
При грубом удалении меню и шаблонных элементов макета со ссылками значительно исказится ссылочная структура, поэтому расчет статического веса сможет стать бессмысленным. Метод относительно безопасен при удалении футера (подвала) сайта. Вернуть при ignore удаленные ссылки не получится без повторного парсинга;
Чтобы сохранить ссылочную структуру и дать возможность краулеру двигаться по ссылкам из удаляемых блоков используйте метод ==nottext== описанный далее;
Так как блоки игнорируются, парсер не найдет ссылки в них для добавления в очередь обхода. Если они будут получены по списку или из файла sitemap.xml, для них не будет рассчитан УВ (уровень вложенности от главной);
==…==псевдоним имеет смысл указать только для визуализации при работе с инструментом тестирования правил, описанным чуть ниже.
==nottext==
Позволяет не добавлять текст и анкоры из подпадающей под правило области не нарушая ссылочной структуры. Повышает чуствительнось алгоритма поиска неявных дубликатов к тексту из оставшихся областей страницы и ускоряет его пропорционально длине исключенного текста, что ощутимо при удалении больших меню со ссылками. Ссылки (уже без анкоров) остаются видимыми и учитываются по правилам, что позволяет краулеру находить и двигаться по ссылкам самостоятельно, как обычно, найдя таким образом все доступные страницы. Таким образом, остается возможность правильно рассчитать статический вес в отличие от метода ==ignore==, который пусть и работает несколько производительней, но удаляет область полностью, включая ссылки. Если на сайте имеются секционные теги <NAV> или <FOOTER>, они являются первыми кандидатами на использование метода (конечно, если на сайте они указаны правильно и не затрагивают важного контента).
▼
Важные моменты:
Если метод затронет первый заголовок <h1>, это скажется на его отображении в главной таблице с данными (может быть показан и последующий незатронутый методом H1, если их несколько) и может повлиять на оценку дубликатов (так как он имеет повышенное влияние). Также возможно сообщение в аудите о пустом H1;
Правило может быть указано только в текстовом поле разметки ссылок;
Метод не окажет влияние на заголовок <title> страницы и meta description;
Допустим только чистый метод ==nottext==псевдоним и сочетание c # в виде ==#nottext==псевдоним;
Указанный в конце псевдоним должен быть максимально коротким, так как им помечаются ссылки. Этими же псевдонимами можно исключать ссылки из расчетов при перерасчетах после парсинга;
Так как может быть не более двух меток для ссылки, если вторая будет занята, она будет перезаписана на текущий (в других методах назначенные метки не перезаписываются);
Другие правила и методы извлечения продолжают действовать внутри затронутых блоков.
Отдельные моменты при веб-скрейпинге:
Все методы извлечения, кроме innerHTML и outerHTML, производят очистку пробелов и переносов строк по краям.
Данные со страниц с директивами noindex, none и disallow не берутся (робот, для которого проверяются директивы, выбирается в настройках);
Страницы с canonical и clean-param всё же обрабатываются, но с соответствующей пометкой в выгрузке (признанные эвристически недействительными рекомендация canonical или clean-param также будут указаны);
Если условию отвечает несколько полей в одном документе, они будут перечислены через <.>;
При бесконечной прокрутке подгрузятся только те данные, загрузка которых активируется первым видовым экраном (прокрутка не осуществляется);
Если целью парсинга является веб-скрапинг данных (например, парсинг сайта конкурента) и не нужны подробный аудит и расчёты — используйте режим ускоренный web scraping;
Парсинг лучше начинать с главной страницы, иначе парсер не сможет рассчитывать уровни вложенности (УВ) страниц, а это может вызвать зацикливание краулера в случаях, когда УВ растет до бесконечности из-за того, что движок сайта ошибочно добавляет в URL повторные фрагменты;
Большие выгрузки разделяются на файлы по 200mb каждый;
Парсинг сайтов конкурентов легален в большинстве стран, в любом случае стоит опираться на национальное законодательство страны, где расположена компания и сервер исследуемого сайта. Разработчики LinksTamed поддерживают только легальный парсинг собственных и доверенных пользователю сайтов, чтобы отвечать правилам интернет-магазина Chrome;
Нельзя получить доступ к отдельным пунктам option списка select, при этом содержимое доступно для скрейпинга на более высоких уровнях DOM-дерева, включая получение select в целом с его option.
Отдельные моменты при разметке ссылок:
▼
Псевдоним можно назначить как самой ссылке, так и родительскому контейнеру любого уровня. Когда правилу отвечает контейнер (например, тег NAV) всем ссылкам во всех дочерних слоях будет присвоен указанный ==псевдоним. Отметка внутри контейнера уже не может быть отменена, но можно использовать какие-то уточняющие псевдонимы;
Используйте макисмально короткие псевдонимы для удобного отображения в таблице и визуализации в режиме тестирования;
Исключать размеченные ссылки из расчетов и таблиц можно также и после парсинга, проводя различные перерасчеты;
Каждой ссылке в документе может быть назначено не более 2-х псевдонимов (два первых сработавших правила при обходе DOM-дерева). Если несколько правил касаются одной ссылки, сначала будут назначены те, что начались на более высоком уровне (с / или //).
В ситуациях, когда ссылка может подпасть под более чем два правила (лучше избегать подобных ситуаций), необходимо учитывать последовательность обработки правил, которая не совпадает с последовательностью в текстовом поле: для начавшихся на одном уровне вложенности правил последовательность обработки задается по типу первого правила строки: id=!*→id=точное→id=*→
class=!*→class=точное→class=*→
tag[n]=→tag[-n]=→TAGname[n]→tag= и TAGname.
Порядок обработки * в первом правиле строки идёт от большей длины фрагмента к меньшей, а если она одинакова, то так:
**x→*x→x**→x*→**→* (* не с краю могут быть только вторичными).
Вторичные условия (после ;) обрабатываются в порядке добавления в правила после срабатывания первого условия и их количество и длина до * не имеет значения, однако правило после / обрабатывается раньше правил начавшихся на этом или более низком уровне DOM-дерева, а / раньше //, так как / является более точной связью.
Инструменты тестирования правил
Запустите пробный парсинг с визуализацией найденных элементов прямо на страницах в браузере. Инструмент находится в раскрываемой секции Web Scraping — парсинг данных по признакам в коде на главной странице LinksTamed.
Если для тега было найдено правило, поверх него будет наложен темный полупрозрачный слой с пунктирной рамкой ( салатовой для Web Scraping и фиолетовой для разметки ссылок). Внутри этого полупрозрачного слоя будет небольшой блок с названием псевдонима с уже уникальным оттенком для всех псевдонимов этого правила. На иллюстрации можно увидеть пример, где в плитке на странице категории распарсена ссылка в заголовке. Если для этого тега сработало несколько правил, они будут перечислены в одном этом полупрозрачном слое. Если в одном из дочерних слоев сработает своё правило, его слой будет расположен под этим, а полупрозрачный слой станет в этом месте немного темнее за счет двойного наложения полупрозрачных слоёв.
Цветной блок псевдонима внутри полупрозрачного слоя имеет (чекбокс), 🔎 и ❌:
Если нажать , псевдоним и слой исчезнут на 4 секунды, а все подпадающие под правило элементы страницы начнут мигать. Если есть другие места, где этот псевдоним сработал, они также будут мигать, но их полупрозрачные слои не будут скрыты. Все одинаковые псевдонимы будут мигать красным. Через 4 секунды слой появится снова в полупрозрачном виде. Элементы продолжат мигать, пока не будет снята галочка с вновь появившегося чекбокса. Временное скрытие используется для доступа к нижерасположенным полупрозрачным слоям без удаления вышерасположенного слоя.
Если нажать ❌ — это удалит цветной блок псевдонима. Если удалить все псевдонимы в блоке, полупрозрачный слой также исчезнет. Если элементы мигали, они продолжат мигать и после удаления блока.
Инструмент 🔎 позволяет просмотреть, какие данные подпали под правило для всех экземпляров этого правила. Для парсинга данных показывается итоговое значение, которое будет записано в ячейку таблицы в выгрузке, а при разметке ссылок — все ссылки, которые подпали под правило.
▼
Важные детали:
Для проверки различных шаблонов на страницах можно указать до 10 URL-адресов из разных доменов;
Если в процессе тестирования страницы недообрабатываются или происходит превышение таймаутов ожидания, значит введенное правило содержит ошибки, из-за которых правила стали слишком обобщенными и парсятся слишком большие объемы информации, например, Веб-скрейпинг с помощью правила div==псевдоним приведет к получению текстового содержимого всех тегов div на странице, в том числе и вложенных друг в друга. Крупная страница просто зависнет или аварийно завершится;
Парсер анализирует только те данные, которые были загружены первым видовым экраном. При прокрутке и прочем взаимодействии с исследуемой страницей могут подгрузиться теги, которые останутся неразмеченными.
Если найденный тег перестал существовать в процессе вашего взаимодействия со страницей, например, удален при прокрутке, его полупрозрачный слой станет красным (именно основной, а не цветной внутри). Это значит, что его содержимое обработано и учтено. При этом стоит убедиться, что тег перестает существовать именно при вашем взаимодействии со страницей, а не при каких-то временных промежутках (т.е. отсутствовал уже сразу, как вы открыли вкладку), так как такое поведение может быть нестабильным (где-то успеет пропарситься, а где-то нет, поэтому возможно нужно будет увеличить таймауты).
По умолчанию краулер не дает загрузиться изображениям и видео на страницах (извлекая лишь тип файла и код ответа HTTP), однако для визуального удобства можно разрешить их загрузку для пробного парсинга, поставив соответствующую галочку в опции под текстовым полем ввода адресов для тестового парсинга. Обратите внимание, что при этом время загрузки увеличится и может не хватить текущих таймаутов ожидания в настройках, тестировать таймауты следует в обычном режиме;
Также, уже во время парсинга и после, можно использовать таблицу проверки корректности извлекаемых данных, которая позволяет просматривать обобщенную информацию для поиска аномалий. Она покажет, сколько обычно срабатывает правил Web Scrasping и на каком количестве страниц, как часто они срабатывают повторно, какова минимальная, средняя и максимальная длина данных записываемых в ячейку выгрузки. Для более глубокого исследования корректности извлекаемых данных можно делать пробные выгрузки в формате CSV прямо во время сканирования сайта. Для самой базовой проверки корректности данных используется таблица слева от текстового поля ввода правил Web Scraping.
Памятка по синтаксису DJpath в виде сжатой таблицы: (ссылка на эту таблицу есть в интерфейсе LinksTamed под текстовыми полями для ввода правил)
Тип (регистронезависимое, пробелы удаляются)
Оператор сравнения
Доступные значения (значения указываем без внешних кавычек из кода)
Затраты на обработку (про влияние * см. Примечания)
Первое условие в строке правила
TAGname = TAG=TAGname
=
TAGname -точное, регистронезависимое название тега;
n — порядковый номер среди всех прочих тегов уровня;
nn — порядковый номер среди именно этого вида тегов
1
TAG[n]=TAGname
3
TAG[-n]=TAGname
4
TAGname[nn]
4
ID=x = @ID=x
x (точное, регистрозависмое), * и ** только краям: x*, x**, *x, **x, *, **, =!* (точное)
2
CLASS=x = @CLASS=x
2
Последующие условия в строке правила
Разделители условий
;(и), /(сл. уровень), //(все уровни внутри)
5, 6 , 6 — 8
TAGname = TAG=TAGname
=, =!
TAGname — точное, регистронезависимое название тега;
n — порядковый номер среди всех прочих тегов уровня;
nn — порядковый номер среди именно этого вида тегов
5
TAG[n]=TAGname
7
TAG[-n]=TAGname
8
TAGname[nn]
8
ID=x = @ID=x
x (точное, регистрозависимое), xX (точное, регистроНЕзависимое);
* и ** — любые сочетания (в том числе посередине);
| (логический оператор «или» внутри значения);
при =! с |, условие истинно, если не равен тому и другому;
в TEXT= заменяем на ** переносы строк и границы контейнеров без пробелов, а также *|";
если в значении есть =;[^ и ! (если первый) помещаем значение в кавычки (="…" или =!"…")
5.5
CLASS=x = @CLASS=x
5.5
@атрибут_тега=x
6
TEXT=xX
7 — 8
LINKto=x
псевдоним правила выше в DOM-дереве
6
$стиль=x
=, =!
x (точное, регистрозавимое, без кавычек, если их нет в DevTools)
8
=<, =>
n (точное число)
9
==…== (опциональное) В текстовом поле разметки ссылок поддерживаются только ==, ==#==, ==##==, ==NOTadd==, ==#NOTadd==, ==##NOTadd==, ==ignore==, ==#ignore==, ==nottext==, ==#nottext==
Методы прекращения: # (найти 1 раз и больше не искать правило), ## (найти и остановить скрапинг и разметку ссылок), NOTadd (найти не добавляя — просто ссылка для LINKto), ignore (полностью игнорировать блок), nottext (игнорировать текст, но не ссылки)
-0 — -9
Методы извлечения (только веб-скрейпинг):
innerText (и если вообще не указан),
textContent,
innerHTML, outerHTML,
nodeValue,nodeValueFIRST,nodeValueLAST,
@атрибут_тега,
^, ^(n),
@@@DISC,
@@@DISC[старый_фрагмент_url,новый_фраг]
+1
+0 +2, +2
+1, +0, +1
+0 +1,+1 — +2
+9 +9
==
псевдоним или [группа] после одинакового ==…==
Другие условия
[url=…]
=, =!
Должен начинаться с url=*, url=** или url=http;
Может содержать любые сочетания *, **, | (внутри url=), а также ;url= («или»);
Используем для больших сайтов режим ускоренный web scraping;
# в начале строки превращает её в комментарий;
"*~| недопустимы как часть пользовательского значения;
Недопустимы как часть пользовательского значения без обрамления в двойные кавычки (="…" или =!"…"): =;/^] и ! (если он первый в пользовательском фрагменте). Используйте * и ** для их замены.
В псевдониме запрещены ; и ==;
Пробелы игнорируются: по краям типа значения, значения TAG=, TAG[n]=, TAG[-n]=, LINKto=, $, все между ==…==, а также по краям псевдонима, поэтому их можно использовать для выравнивания правил;
Производительность и влияние * (быстро→чуть медленнее):
=!*→=x (точное)→=*→=**→
( +1 к затратам на обработку правила)→=x**→=x*→
(ещё +1 к затратам на обработку правила)→=**x→=*x→
(ещё +1 к затратам на обработку правила)→=другие*сочетания|(«или»)и**звездочек;
Абсолютные пути для / начинаются с тега HTML, хотя этот подход не рекомендуется — DJpath оптимизирован для коротких относительных путей;
TAGname, TAGname[n], id=, class= с точными значениями (без *) и / являются совместимыми c путями в XPath, поэтому их можно копировать из DevTools. //* в начале строки при копировании пути XPath в DevTools ничего не делает, т.к. является частью синтаксиса XPath, [@id=…] (условие со значением в квадратных скобках) — также служит для совместимости и не оказывает никакого влияния.
Замечания по производительности условий
Примерная производительность условий отмечена в последнем столбце памятки по синтаксису DJpath;
Первое условие строки самое производительное, если правило многосоставное, в начало следует добавлять как можно более производительное и редко срабатывающее условие;
* и ** замедляют правила, при этом звездочки не с краю и | замедляют сильнее (сила отражена в Примечания в памятке);
Если class=, id=, tag= и TAGname, TAGname[n], tag[n]=, tag[-n]= встречается как первичное один раз в пределах правил на странице, оно будет работать чуть быстрее;
[url=…] позволяют вообще не добавлять правило на страницу, таким образом, если будет добавлено только одно правило, может сработать предыдущий пункт.
 Если для тега было найдено правило, поверх него будет наложен темный полупрозрачный слой с пунктирной рамкой ( салатовой для Web Scraping и фиолетовой для разметки ссылок). Внутри этого полупрозрачного слоя будет небольшой блок с названием псевдонима с уже уникальным оттенком для всех псевдонимов этого правила. На иллюстрации можно увидеть пример, где в плитке на странице категории распарсена ссылка в заголовке. Если для этого тега сработало несколько правил, они будут перечислены в одном этом полупрозрачном слое. Если в одном из дочерних слоев сработает своё правило, его слой будет расположен под этим, а полупрозрачный слой станет в этом месте немного темнее за счет двойного наложения полупрозрачных слоёв.
Если для тега было найдено правило, поверх него будет наложен темный полупрозрачный слой с пунктирной рамкой ( салатовой для Web Scraping и фиолетовой для разметки ссылок). Внутри этого полупрозрачного слоя будет небольшой блок с названием псевдонима с уже уникальным оттенком для всех псевдонимов этого правила. На иллюстрации можно увидеть пример, где в плитке на странице категории распарсена ссылка в заголовке. Если для этого тега сработало несколько правил, они будут перечислены в одном этом полупрозрачном слое. Если в одном из дочерних слоев сработает своё правило, его слой будет расположен под этим, а полупрозрачный слой станет в этом месте немного темнее за счет двойного наложения полупрозрачных слоёв.