Бесплатно найдите похожие страницы с дублирующим контентом и устраните недочёты, которые могут вызвать проблемы с продвижением сайта. Фирменный алгоритм сэкономит время за счёт фокусировки анализа на важных словах и зонах документов. Удобные инструменты для работы с дублями, рекомендации и умная визуализация ценных различий позволит быстро устранить важные проблемы с дубликатами на сайте. Встроенные алгоритмы также проверят уже имеющиеся Canonical и Clean‑param. Более того, LinksTamed автоматически склеит все достаточно похожие страницы и отвечающие базовым требованиям страницы пагинаций (категорий товаров и многостраничные статьи), чтобы вы могли увидеть более реалистичную структуру сайта. Продвинутые пользователи могут также исключать шаблонные блоки документов и проводить мультидоменные сравнения по спискам.
Эвристический поиск дубликатов на сайте — метрика «дубли на грани»
Хотите найти и удалить дубли на сайте? Просто запустите парсинг в LinksTamed и он по умолчанию найдёт все частичные дубликаты, похожие по тексту!
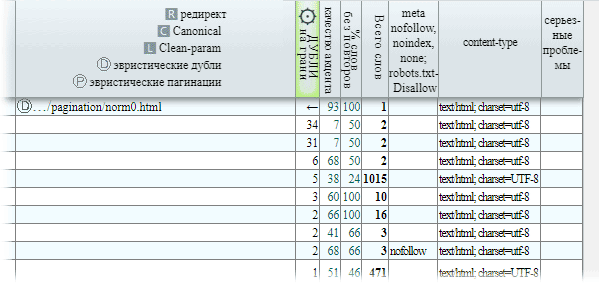
Парсер обходит домен по правилам для выбранного в настройках бота поисковой системы: сканирует страницы сайта, включая асинхронно погружаемый JavaScript контент, после чего самостоятельно проводит массовый поиск частичных дубликатов. Результаты отображаются на главной странице парсера в столбце итоговой таблицы ⚙ДУБЛИ на грани в виде количества похожих документов для каждой страницы. Значения доступны после окончания краулинга и финальных расчётов.
▼
На иллюстрации выше, где изображен фрагмент итоговой таблицы, Вы можете видеть, что часть дубликатов вместо числового значения могут иметь ←. Это значит, что страница является дубликатом с очень похожим контентом, который превысил порог эвристического склеивания (набора критериев в движке парсера) и был объединен с канонической страницей автоматически, чтобы предоставить более реалистичную структуру сайта и более точные расчеты таких параметров как, например, статический вес страниц. Вам остается лишь убедиться визуально, что такие страницы не имеют самостоятельной ценности и указать в коде (или же, что сложнее, HTTP-заголовке) неканонической страницы canonical c URL-адресом из соседнего столбца, который будет иметь метку 🅓 (эвристический дубликат). При работах на сайте Вы можете также закрыть от индексации такие неканонические страницы с помощью noindex, none, Disallow, сделать редирект с HTTP-кодом 301 или, наоборот, провести работы по уникализации, если оба документа имеют дополненную ценность для пользователя.
Для страниц, которые уже имеют указание на каноническую версию через рекомендацию canonical, дубликаты не отображаются с целью уменьшения количества дублей «на грани», не требующих от пользователя дальнейших работ по дедубликации. В любом случае в строке самой канонической страницы можно посмотреть все страницы на которые она похожа (в столбце ⚙ДУБЛИ на грани), а также те, которые приклеены к ней, но для которых она сама не является полным или частичным дубликатом (в столбце ссылок с весомin). Это можно сделать через всплывающее окно с деталями, о котором рассказано в следующем разделе. LinksTamed также проверяет правильность уже имеющихся на сайте рекомендаций canonical: если для каких-либо страниц указанные на них canonical признаны недействительными, их список будет перечислен в таблице с результатами аудита, а в самом столбце …🅲Canonical… такая ссылка будет отсутствовать. LinksTamed делает множество проверок и предупредит даже если из двух страниц вы выбрали канонической неоптимальную, например, из-за того, что на неё ведёт меньше входящих ссылок, чем на той, в коде которой указан canonical.
Как отключить эвристический поиск дубликатов по контенту
В информационном блоке Этапы работы парсера снять галочку в разделе этапа ❷ Эвристический поиск неявных дублей, углубленный анализ текста. В процессе анализа дубликатов также возможно остановить поиск с текущим количеством найденных дубликатов страниц нажав в этом разделе кнопку . Парсер продолжит работать с теми дубликатами, которые были найдены на момент прерывания поисков. Оценка релевантности текста ключевым тегам, которая собирается попутно, также будет прекращена. Дубликаты продолжают склеиваться по имеющимся canonical и Clean-param даже без анализа контента (после простой проверки доступности документа).
Окно детального просмотра дубликатов страницы
Любое цифровое значение в столбце ⚙Дубли на грани кликабельно и вызывает окно, на котором дубли страницы раскрыты детально:
Внутри всплывающего окна показаны и рассортированы по разделам не только частичные дубли на грани для данной страницы, но и эвристически склеенные и имеющие действительную отметку canonical документы. Имеется возможность сделать выгрузку данной таблицы в формате CSV.
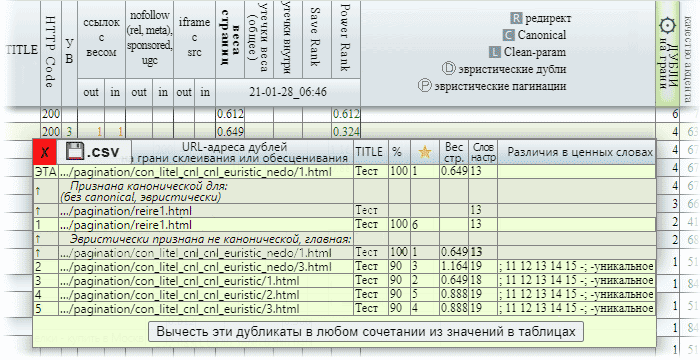
Одним из двух наиболее интересных показателей в окне является столбец с заголовком ★ , значения которого показывают, насколько предпочтительна страница (в строке) с дублирующим контентом на роль канонической страницы, исходя из её авторитетности. Значения подсказывают, что лучше всего проставить канонические ссылки со страниц с большим значением, указав страницу с меньшим (разумеется, если после осмотра вы пришли к выводу, что копии не имеют дополненной ценности). % соответствия при этом не учитывается при создании рейтинга. Поскольку вы можете решить, что в таблице несколько подгрупп и для каждой подходит своя каноническая страница, минимальное число для каждой такой подгруппы будет также указывать на оптимальную.
Второй из двух наиболее интересных столбцов Различия в ценных словах показывает самые ценные слова, которые есть только у страницы ЭТА или её дубликатов.
Фирменная визуализация различий от LinksTamed показывает именно те словоформы, которые высоковероятно имеют реальную ценность для быстрого принятия решений в плане SEO. Больше не нужно сравнивать документы визуально, и тратить время на изучение не влияющих на SEO дублирующих участков контента. Преимущество отображения несоответствий в виде списков проявляются при выгрузке всех дубликатов в файл с таблицей в формате CSV — на данный момент это единственная в мире эффективная технология, позволяющая изучать дублирующие страницы вне интерфейса SEO-софта.
Обязательные для понимания детали по визуализации различий:
Строка со страницей ЭТА никогда не содержит различий, так как все сравнения идут относительно неё в строках её дубликатов;
В ячейке отображаются слова с наибольшим весом и ценностью, которые есть только у страницы строки и нет у страницы ЭТА, для которой было вызвано окно;
Слова, которые есть только у страницы ЭТА начинаются с минусом (то есть этих слов у страницы строки нет). В примере на иллюстрации выше только ЭТА имеет словоформу «уникальное», а вот все остальные имеют цифры «11 12 13 14 15», которых нет в ЭТА. То, что выбраны столь незначительные различия как цифры, подсказывает, что более ценных различий нет;
Показывается не более 5 слов без минуса и не более 5 с минусом. Если слов менее пяти, значит только это количество уникальных слов имеется у страницы и нет у её дубликата;
Если слова не рядом, они идут через запятую ,;
Если есть различия в тайтле, они идут перед символом точки с запятой ;. Если различий в тайтле станицы нет — в начале будет ;. Если при сравнении двух страниц уникальных словоформ не нашлось вообще, в столбце % будет указанно 100, а ячейка будет пуста. В примере на прошлой иллюстрации различия в TITLE-заголовке страницы отсутствуют, поэтому перед ; и -; ничего нет;
Если между двумя словами удалены при парсинге незначащие части речи и оба они попали в различия (по спискам минус-слов на странице ПАРАМЕТРЫ), они будут без запятой;
Слова идут по порядку, как в DOM-дереве, то есть после выбора 5 наиболее редких слов последовательность восстанавливается;
Слова в ссылках игнорируются для целей визуализации и если на одной странице ссылка на себя перестает быть ссылкой, а на другой останется, оно может быть указанно как различие;
Помните, что показываются похожие документы относительно страницы ЭТА, поэтому другие страницы могут быть похожи на данную страницу, но если сравнивать наоборот, процент схожести может значительно отличаться, что следует проверять через строки этих страниц в основной таблице.
Обратите внимание, что значения столбца Различия в ценных словах рассчитываются в процессе постобработки, после того, как данные уже выведены и требует некоторого времени. Подробнее в разделе «Постобработка...»
Умный % соответствия
Поиск дубликатов страниц на сайте просто по участкам текста, которые имеют одинаковую ценность, не всегда эффективен: специалисты сталкивались с огромным количеством признанных схожими из-за неважных деталей документов, особенно при малом количестве уникального контента на страницах, например, на карточках товаров. Поиск дублей страниц в LinksTamed работает иначе и выполняет сравнение деликатнее большинства алгоритмов благодаря фирменному программно-аппаратному комплексу решений, на которые подана патентная заявка.
Основные приемы повышения качества расчёта процента соответствия дубликатов по контенту в LinksTamed:
Веса слов
▼
Одно из важнейших отличий от классических алгоритмов поиска дубликатов страниц на сайте в том, что LinksTamed задает различную ценность словоформам на странице. Веса слов в классическом понимании отражают частоту употребления слова в интернете. Это может быть вес общий для всех словоформ слова или отдельный вес для каждой из них. Также словосочетания в ПС могут объединяться в мультиворды и иметь собственный, более высокий вес. В отличие от поисковых систем, LinksTamed использует локальные веса словоформ, точность расчёта которых зависит от количества страниц для самообучения (рекомендуется не менее 50 страниц). Иными словами, чем чаще на других страницах сайта встречается слово, тем меньшее влияние на итоговый процент схожести оно оказывает.
Минус-слова
Чувствительность алгоритма повышена за счет удаления минус-слов – списка самых лёгких словоформ, вычисленных специально для этого алгоритма при запросах к одной из ПС. Они указанны на странице настроек в виде редактируемого списка отдельно для английского, русского и украинского языков. Эти слова полностью игнорируются при сравнении дубликатов, что ускоряет поиск, но может вызвать искажения, в очень редких случаях способных оказать влияние на расчёты, поэтому на всякий случай необходимо знать об этой особенности.
Полнотекстовый поиск
Большинство алгоритмов осуществляющих поиск дубликатов используют разбиение на шинглы — берутся участки текста от 2 до 15 и более слов, преобразованные в hash-строку (то есть в одно слово), чтобы ускорить поиск. Таким образом, даже если одно незначительное слово отличается, будет засчитано несоответствие равное количеству слов в этом шингле. С учетом того, что все слова в таком участке имеют один вес, в результаты попадают лишние дубликаты. LinksTamed сравнивает каждое слово и принимает во внимание их положение относительно друг друга, при этом все равно работает в несколько раз быстрее большинства алгоритмов, благодаря фирменным ускорителям и работе сразу на двух ядрах процессора.
Дополнительный вес слов в TITLE-заголовках и H1
Поисковые системы могут не признавать дубликатами идентичные по тексту документы даже из-за различий в виде одного слова в заголовке. Данный фильтр дополнительно регулирует процент соответствия в таких случаях, обычно в пределах 1%. Распознание ценности слова, которое применяет ПС, эмулируется в LinksTamed весом слов. Кроме того, в алгоритме имеется специальный фильтр дополнительного смысла, проверяющего обратную совместимость — если другая страница имеет дополнительные качества в заголовках, процент соответствия немного снижается, так как приклеивать её к такой странице было бы неправильно. Иными словами, если страница содержит все слова другой страницы, её процент идентичности может быть несколько ниже 100%.
Уменьшение влияния шаблонных элементов
▼
Практически на любых страницах сайта присутствуют шаблонные элементы. Они могут составлять большую часть контента на странице. Чтобы повысить чувствительность сравнения, алгоритм использует оригинальную технологию снижения влияния шаблонных областей. Для каждой ссылки отбирается акнор, а также 16 слов до и после, после чего все подобные участки признаются для любых документов шаблонными при достяжении определенного порога встречаемости. Для эффективного определения шаблонных элементов алгоритму нужно не менее 15-ти страниц с этими участками. Если шаблонный фрагмент встречается на 80-ти и более страницах, он исключается из расчётов уже полностью. Эффективность подавления снижается для чистых участков текста (такие любят делать в нижней части страницы) с более чем 30 словами (минус-слова не считаются, так как уже удалены), а также блоков, которые выглядят как ссылки, но не имеют тега A. Когда на странице экстраординарное количество ссылок и шаблонных элементов, а также если шаблонный блок имеет переменные (например, хаотичное облако тегов), может понадобиться один из методов ручного исключения блоков (описывается в соответствующем разделе этой страницы).
Таким образом, несмотря на то, что процент соответствия отражает скорее соответствие смыслу, а не просто количество совпавших слов, его значения, в подавляющем числе случаев, являются интуитивно более понятными и выглядят более естественными при работе с дубликатами.
Почему минимальный процент соответствия 85
В процессе использования парсера Вы можете обратить внимание, что дубли страниц ниже 85% (которые, как было сказанно выше, не являются просто процентом совпавших слов) не отображаются в результатах. Данный минимальный процент соответствия, который попадает в таблицу, отвечает двум рациональным величинам, объясняя также название самой метрики «дубли на грани»:
Во-первых, он отражает потенциальную способность найденных страниц оказать негативное влияние на продвижение;
Во-вторых, отражает минимальную способность страницы быть объединенной с найденными для неё похожими страницами с помощью указания рекомендации canonical. Если бы Вы попытаетесь склеить страницы, которых нет в найденных дубликатах, повышается вероятность, что поисковая система признает такое указание ошибочным и проигнорирует. LinksTamed также признает явным образом указанные дубликаты со степенью схожести ниже 85% недействительными. Помните, что canonical и Clean-param – это всего лишь рекомендации.
Всё это позволяет убрать дубли, которые не представляют никакой ценности для специалистов и не пригодятся при работе с сайтом.
Постобработка: автоматическое доуточнение результатов поиска дубликатов
▼
После окончания всех расчётов и вывода результатов алгоритму требуется ещё некоторое время для уточнения % соответствия дубликатов от 97% и выше (в большую сторону), а также визуализации различий ценных слов для всплывающих окон с дубликатами и соответствующего столбика выгрузки дубликатов в CSV.
Постобработка не влияет на уже сделанные расчёты, в том числе не меняет отображаемое количество дубликатов в таблице и служит лишь для визуализации различий.
Необходимость дополнительной обработки вызвана тем, что расчёт последних 2-3% основным алгоритмом занял бы более 20% времени. Постобработка работает по другому — в процессе поиска ценных различий на уточнение % вообще не тратится дополнительного времени, при этом пользователь уже имеет доступ ко всем готовым данным. Сообщение об окончании постобработки отображается в блоке Основные этапы парсинга и обработки данных.
Фильтрация найденных дубликатов
LinksTamed предлагает пользователю два вида инструментов для уменьшения количества копий страниц с дублирующим контентом:
В заголовке ⚙Дубли на грани есть кнопка в виде ⚙, нажатие на которую откроет окно, где можно отсечь дубликаты по минимальному проценту сходства. Здесь также можно просмотреть количество дубликатов с определенным процентом. Выберите 100% и в таблице останутся только полные копии, такие как технические дубли страниц с уникальными адресами и крайне малым различием в контенте, а также те, что были склеены как эвристические дубликаты. Кнопка позволит показать все дубли по умолчанию, включая скрытые инструментом в следующем пункте. Если фильтр затрагивает значение в таблице, оно станет оранжевым.
В нижней части окна просмотра дубликатов страниц (иллюстрация есть выше) имеется кнопка . Фильтр переносит в раздел Скрытые ручным фильтром дубликатов (внутри всплывающего окна с деталями) URL-адреса, которые являются дублями «на грани» для этой страницы в любом их сочетании (не только с этой, но и друг с другом) во всех окнах, а также вычитает их количество в таблице. Если фильтр затрагивает цифровое значение в основной итоговой таблице, оно станет оранжевым. И хотя такой подход может показаться агрессивным, он наиболее эффективно помогает распутать сложные пересечения схожих страниц. Скрытые фильтрами копии страниц продолжают участвовать в расчётах, меняется только их отображение.
Удаление дублей из отображаемых в таблицах данных действуют также и на .
Выгрузка всех дубликатов в формате CSV
Все полные дубликаты и частичные копии страниц от 85%, а также информацию о пагинациях можно выгрузить через на главной странице парсера.
В выгрузке предоставляется исключительно подробная информация для работы с дублирующим контентом и дальнейшей оптимизации сайта вне интерфейса программы:
▼
TITLE-заголовки и URL-адреса страниц;
Насколько подходит на роль канонической;
URL уже канонический для;
URL канонической страницы (с отметкой, если признана эвристически, то есть без canonical);
Дубликатов на грани у URL (цифровое значение или ←←←←, указывающее на ячейку с URL-адресом признанной эвристически канонической страницы);
УВ (кликов от главной);
Статический вес страницы (если не приклеена к другой);
Входящих ссылок (передающих вес), включая приклеенные;
Слов (на странице);
Качество акцента;
Сколько раз уже встречалась выше как вторичная (помогает быстрее ориентироваться, если таблица еще не сортировалась);
Есть неучтенные дубликаты (фильтры или ограничения, например, удалены в ручную или превышены пределы на общее количество дубликатов для выгрузки).
К каждой странице, для которой есть дубликаты «на грани», в дополнение к общим полям, для всех её дубликатов расписаны:
% различия;
Разница в ценных словах
Несколько важных моментов при выгрузке:
Ручные фильтры дубликатов действуют и на выгрузку;
Если сделать выгрузку не дождавшись окончания процесса визуализации различий в процессе постобработки (описано в отдельном разделе), значение поля будет отображено как NOT_LOAD. Если для строки с NOT_LOAD процент соответствия от 97% и более, он также не был уточнен и может быть от 97 до 100%.
Кодировка файла «Юникод UTF-8» в формате CSV c разделителем в виде точки с запятой ;). В старых версиях MS Excel могут возникнуть проблемы с кодировкой. В этом случае удобнее всего открывать файл в OpenOffice Calc или поменять кодировку на «Windows-1251» с потерей символов вне латинского и кириллического диапазонов.
Важные моменты относительно поиска дубликатов, которые не вошли в разделы выше:
На данный момент алгоритм рассчитан на работу с сайтами до 160 000 страниц. Для ускорения поисков на сайтах от 20 000 более страниц рекомендуется вручную исключать шаблонные элементы из поисков с помощью методов описанных в разделе «Исключение блоков макета страницы из поисков»;
Скорость поиска дубликатов: в среднем 20 000 страниц в час и зависит от количества контента и мощности ядер процессора;
Мультидоменный парсинг по списку: указание нескольких адресов позволяет искать не только внутренние дубли страниц, но и сравнивать документы из списка с любых доменов. Однако необходимо помнить, что для уменьшения влияния шаблонных элементов нужно не менее 15-ти страниц с каждого домена.
Алгоритм осуществляет поиск неявных дубликатов только на тех страницах, на который смог попасть краулер согласно правилам для выбранного в настройках поискового бота. Отрабатывается JavaScript и подгружается контент, который активизирует первый видовой экран (прокрутка не осуществляется). Если страница исключена из индекса директивами (noindex, nofollow; none; Disallow) или рекомендациями, такими как Clean-param и canonical, а также если на страницу ведут только nofollow ссылки, контент такой страницы не обрабатывается;
LinksTamed индексирует не более 1 048 576 символов или 64 967 слов на документ;
Помимо текста и не удаленных как шаблонные анкоров ссылок, при сравнении страниц учитывается TITLE-заголовок страницы, MetaDescription и описание изображений в атрибуте ALT тега IMG;
LinksTamed сохраняет для каждой страницы до 200 найденных на сайте дублей, но если в сумме будет найдено более 1 500 000, то не более 10-ти для каждой последующей страницы с дублями. Эти пределы могут быть меньше в итоге, так как удаление страниц с работоспособным canonical происходит позже. Если для страницы есть несобранные из-за превышений дубликаты, число в соответствующем столбце будет оранжевым;
Если на сайте менее 50 страниц с нормальным контентом, возможны неточности из-за недостаточного для обучения алгоритма количества страниц. Алгоритм обладает двумя уровнями устранения влияния шаблонных элементов: если на сайте менее 15-ти страниц с одним шаблоном, не сработает автоматическое снижение ценности шаблонных элементов, а если на сайте менее 80-ти страниц с одинаковыми фрагментами, то они не могут быть удалены полностью (будет лишь снижена их ценность, если таких шаблонных элементов не менее 15-ти);
Вы можете проводить сравнение страниц по спискам, в том числе и с разных сайтов, однако следует учитывать, что снижение влияния шаблонных элеметнов на итоговый % соответствия возможно только если вы предоставили не менее 15-ти страниц с одинаковым шаблоном. При 80-ти страницах с одинаковым шаблоном сработает фильтр уже более полного удаления шаблонных фрагментов, которые есть на всех этих страницах;
Обратите внимание, что в списке дублей могут быть страница с гораздо большим количеством контента - это значит, что она не является дубликатом в классическом понимании этого слова, а содержит почти весь набор текущей страницы, вследствие чего может быть признана канонической, а текущая страница будет к ней приклеена;
Список страниц с идентичными TITLE-заголовками страницы отображается отдельно в аудите;
Функционал модуля ориентирован не на работу с отдельными фрагментами текста, а на поиск страниц и визуализация различий, которые могут оказать влияние на позиции сайта: вылиться в виде низких позиций в ПС из-за большого количества «мусорных» документов, привести к исключению страниц из индекса или склеиванию нескольких страниц алгоритмом поисковой системы — всё о чём действительно стоит беспокоиться SEO-специалистам, Web-мастерам и владельцам сайтов.
Исключение блоков макета страницы вручную
Модуль Web scraping в составе LinksTamed позволяет находить и производить действия с тегами и их содержимым на странице.
За счет исключения шаблонных элементов в макете страницы по вашим правилам, Вы можете повысить чувствительность поиска дублей, например, чтобы минимизировать влияние шаблонных элементов на разных сайтах, и увеличить скорость анализа больших сайтах. Более того, исключив все ненужные области, можно анализировать определенный блок контента.
Парсер поддерживает два метода, которые позволяют не учитывать элементы макета на странице при оценке дубликатов:
Метод ==nottext== удаляет только текст и анкоры, оставляя при этом сами ссылки, чтобы краулер мог находить новые URL-адреса в этом блоке для их последующего обхода, что обеспечит правильный расчёт статического веса страниц.
Метод ==ignore== заставляет полностью игнорировать участок макета, включая ссылки, и может значительно ускорить парсинг на всех его этапах. Метод вполне безопасно применять для подвалов или если вы хотите исключить некоторые блоки с хаотически изменяемым контентом (например, облака ссылок) из расчётов статического веса. Стоит отметить, что модуль веб-скрейпинга имеет другие способы размечать ссылки для дальнейших манипуляций с ними, включая исключение из расчётов с возможностью их повторного восстановления для перерасчётов;
Текст option списков select индексируется ПС, но в LinksTamed игнорируется, так как на некоторых сайтах большие списки оказывают слишком большое влияние.
Важные моменты:
Правила необходимо указать до начала парсинга, поэтому рекомендуется использовать инструмент тестирования, который позволит визуализировать правила на 1-10 страницах прямо в окне браузера;
Методы ==nottext== и ==nottext== повлияют на другие метрики оценки текста, такие как автооопределение языка или оценка релевантности.
Исчерпывающую информацию о данных методах исключения блоков макета, а также примеры для быстрого создания и тестирования правил, читайте на странице с описанием функций Веб-скрейпинга.
Также обратите внимание, что на странице ПАРАМЕТРЫ можно заблокировать внешние ресурсы по домену, в том числе и скрипты с рекламной в виде текста.
Эвристические консолидации
В итоговой таблице отображаются автоматически склеенные после краулинга страницы двух типов:
Эвристические дубликаты
Страница является дубликатом, дублирование контента в которой превысило порог эвристического склеивания (от 98% и выше) и поэтому данный документ объединен с канонической страницей автоматически самим парсером на основе схожести контента. Это происходит если отсутствует или признан недействительным указанный в коде canonical (когда canonical действителен перед URL-адресом в данном столбце отображается 🅲). Значения доступны после краулинга и финальных расчётов. Вам остается лишь указать для таких страниц canonical на самом сайте или запретить их индексацию для устранения эффекта каннибализации в выдаче, а также снижения рисков для поискового трафика и уменьшения трат краулингового бюджета. Также, напротив, вы можете провести работы по уникализации данных, если страницы имеют самостоятельную ценность и потенциал для их уникализации. Консолидация этого типа будет иметь метку 🅓 (Дубликат) перед URL-адресом в столбце …🅓 эвристические дубли…. В случае, если производился поиск частичных дубликатов (включен по ум.), значение в столбце ⚙Дубли на грани, будет указывать на эту ссылку с помощью ←, так как алгоритм определил, что наиболее оптимальная страница уже выбрана и не имеет смысла рассматривать для неё дублирующий контент с участием пользователя. В любом случае в строке самой канонической страницы можно посмотреть её дубликаты и кто ещё к ней был приклеен.
▼
Как склеиваются схожие страницы сайта и почему это может отличаться от результатов в поисковой системе.
Из нескольких похожих страниц алгоритм выбирает канонической ту, что обладает лучшим набором метрик качества, таких как входящие сигналы с других проанализированных парсером страниц сайта или, например, количества текста, а если страницы идентичны, приоритеты определяются порядком, в котором краулер просканировал страницу.
Найденные алгоритмом дубликаты могут быть не склеены в поисковых системах по разным причинам, например, одной из страниц нет в индексе или она проиндексирована не достаточно давно. LinksTamed также не учитывает сигналы с внешних сайтов и не анализирует уникальность изображений с помощью компьютерного зрения, лишь сравнивая их описание в атрибуте ALT. В остальном поиск дубликатов в LinksTamed производит академически верные расчёты и работает деликатнее алгоритмов поисковых систем, которые испытывают проблемы с созданием полной коллекции практически идентичных документов и выбора из них оптимального, особенно если дубликаты появляются в разное время. В результате не самые лучшие документы по текстовым и иным метрикам могут быть основными в выдаче, поэтому результаты могут разниться, однако в целом по распределению и показаниям статического веса в таблице, получается очень близкая картина, потому что при большом количестве дубликатов, получается реалистичное распределение статических весов по разделам.
В любом случае страницы для которых могут быть замечены неточности, имеют серьезные проблемы и требуют работ по их дедубликации, запрету индексации или объединения через указание canonical.
Канонические страницы могут также отличаться при повторных краулингах идентичного сайта:
количество страниц или текста, включая мелкие фрагменты, изменилось, а вместе с ним изменилась и ценность слов, что играет роль при низких процентах соответствия;
недостаточные таймауты привели к недогрузке на случайных страницах важного при оценке контента;
Практически идентичные страницы просканированы в разной очерёдности, что играет роль в некоторых случаях.
Если на сайте есть страницы почти без контента, они будут похожи практически на все страницы сайта. Для таких страниц собирается рационально оправданное количество претендентов на более детальную проверку, где при прочих равных играет роль, в том числе, и порядок сканирования страниц, который может отличаться из-за многопоточности.
Как отключить эвристическое склеивание дубликатов страниц: в раскрываемом разделе Фильтры расчётов статического веса, разметка ссылок и извлечение значений (web scraping) на главной странице LinksTamed в подразделе Другие фильтры поставить галочку в опции Не склеивать эвристически дубликаты…. Если сканирование сайта уже завершено, необходимо провести пострасчёты повторно (пересканирование сайта не требуется). Все страницы, которые имеют рекомендацию canonical всё равно будут склеены по правилам.
Эвристические страницы пагинаций
LinksTamed производит эвристический поиск страниц пагинаций и многостраничных материалов. Указания prev\previous\next служат лишь для целей аудита и проверки эвристической склейки. Консолидация этого типа будет иметь метку 🅟 (Пагинация) перед URL-адресом в столбце …🅟 эвристические пагинации. Значения доступны после краулинга и финальных расчётов.
Чтобы страницы были правильно приклеены к первой странице пагинации, они должны отвечать следующим правилам:
Обладать одинаковым TITLE-заголовоком в основной его части, а также:
Все последующие страницы структуры должны иметь различия в хвосте тайтла в виде признаков постраничного разбиения, такие как цифры и признак в виде слова страница, часть, part, page, сторінка, частина. Разрешается также дополнение в виде из и of с количеством страниц в данном многостраничном материале. Таким образом, поддерживаются русский, английский, украинский и белорусский языки;
Если страницы имеют одинаковые тайтлы страницы без признаков постраничного разбиения, последующие страницы структуры должны иметь признаки в URL-адресе, такие как: page(s)=n или page(s)/n, при этом в аудите всё равно будет предупреждение об одинаковых заголовках документов (правило действует с v. 2.0.0.1).
Первая страница структуры может не иметь дополнительных признаков;
Если проводились работы по уникализации TITLE-заголовков пагинаций (сортировок, фильтров), такие страницы не могут быть склеены между собой, однако возможны комбинации с canonical и, например, страницей
«показать все»
Иметь взаимные ссылочные взаимосвязи в пределах структуры-кандидата на склейку и ссылки на главную страницу пагинации со всех последующих страниц структуры;
1-я страница пагинации должна быть наиболее сильной и не может быть большего уровня вложенности чем последующие;
Ошибочное склеивание страниц означает, что на сайте имеются проблемы с идентичными заголовками, которые необходимо решать
Эвристические канонические рекомендации имеют больший приоритет, при этом LinksTamed способен справится со сложными сочетаниями пагинаций и канонических рекомендаций, объединяя их в единую структуру.
В отличие от дублей, страницы пагинации продолжают показываться в выдаче по запросам, где они продолжают быть релевантными, консолидируются только общие характеристики, поэтому так сложно обнаружить, что они существуют и консолидируются.
Как отключить эвристический поиск и склеивание страниц пагинаций: в подразделе Этапы работы парсера снять галочку в разделе ❹Эвристическая склейка пагинаций.
Проверка и склейка явно указанных canonical и Clean-param
Обработка canonical
LinksTamed проверяет и обрабатывает все канонические ссылки на сайте. Любая страница с указанным в HTML-коде атрибутом rel="canonical" в теге link или canonical в HTTP-заголовкесправка, проходит проверку на схожесть контента, и в случае, если эта рекомендация признана алгоритмом LinksTamed действительной, сигналы неканонической страницы будут объедены с указанной в canonical основной версией страницы. Канонический URL попадет в столбец, содержащий в заголовке …🅲 Canonical…. Если поиск дубликатов по контенту отключен, будет произведена лишь техническая оценка работоспособности канонических рекомендаций. Кросс-доменные канонические ссылки работают только при парсинге по правилам googlebot и для них проверяется только HTTP-код ответа, без анализа контента. Недействительные рекомендации не отображаются в соответсвующем столбце итоговой таблицы, а причины их отсутствия будут указаны в аудите. Какие изменения произойдут в отображаемых данных и расчётах читайте в разделе «В чём проявляется в интерфейсе склейка...»
Обработка Clean-param
LinksTamed единственный в мире общедоступный SEO-софт, способный проверять директиву Clean-param из robots.txt, правилами которой руководствуется yandexbot (и некоторые другие боты) для удаления из индекса страниц с не влияющими на контент GET-параметрами. Функционально она похожа на рекомендацию canonical, предлагая между тем более интересные возможности для массовой фильтрации. Несмотря на то, что Clean-param называется директивой, она является рекомендацией для алгоритмов ПС, причем с более низким приоритетом, нежели canonical. LinksTamed склеивает подпадающие под рекомендацию страницы, объединяя сигналы и сводя их на одной странице. Адрес главной страницы страницы структуры попадет в столбец, содержащий в заголовке …🅻 Clean-param…. Какие именно изменения произойдут в отображаемых данных и расчётах читайте в разделе «В чём проявляется эффект склейки...»
Поскольку алгоритмы Google не учитывают Clean-param компании Яндекс, в парсере она оказывает влияние только при работе по правилам для yandexbot, однако аудит производится в любом случае. Проблемные указания попадают в аудит, а в соответствующем столбце итоговой таблицы указываются только признанные валидными канонические страницы.
Чтобы включить склеивание страниц с помощью Clean-param для парсинга по правилам googlebot (этот бот установлен по умолчанию), поставьте галочку в опции использовать для googlebot Clean-param расположенной под кнопкой . Это может дать более точные результаты склейки страниц, особенно если отключен поиск дублей «на грани», так как высоковероятно, такие страницы будут признаны дубликатами в обоих ПС.
Если для сайта использовался инструмент Google Search Console → Параметры URL с целью удаления GET-параметров, Вы также можете использовать Clean-param для парсинга по правилам для googlebot с целью эмуляции удаляемых там в консоли параметров, хотя, по-хорошему, оба способа должны повторять друг друга, так как выполняют одинаковые задачи. В любом случае LinksTamed найдет все технические дубликаты страниц на сайте, однако именно Clean-param подскажет, что для них не требуется действий по дедубликации.
Приоритет явно указанных рекомендаций выше эвристических консолидаций описанных выше на этой странице. В случае конфликтов, алгоритм попытается адаптировать эвристические консолидации и в любом случае укажет в аудите на проблемы.
Перерасчёты и время на повторный поиск дублей
Поскольку LinksTamed эвристически находит и склеивает дубликаты, а также отменяет недействительные канонические рекомендации, при любых перерасчётах с фильтрами рекомендуется осуществлять поиск дубликатов и пагинаций повторно.
Однако на больших сайтах процесс поиска дубликатов может занимать несколько часов. Если планируется работа с фильтрами после основного парсинга тогда, чтобы без искажений при перерасчётах отключать эвристический поиск дубликатов, необходимо выбрать одну из стратегий:
▼
Изначально искать дубликаты, но включить опцию Не склеивать эвристически дубликаты… в разделе Фильтры…, а после первого парсинга отключить перерасчёты (найденные дубли на грани будут стерты при таком перерасчёте, но текстовые метрики, которые собираются вместе с дубликатами, удалены не будут). Дубликаты продолжат склеиваться без учета контента.
Изначально отключить сканирование в подразделе ❷ Эвристический анализ неявных дублей, качество акцента, возможные опечатки. Будут проводиться проверки канонических рекомендаций без учета контента. качество акцента и % слов без повторов также не будут рассчитаны, как и не будет произведен поиск вероятных опечаток в виде уникальных словоформ. После работы с фильтрами можно включить поиск дубликатов и эвристическое склеивание, сделав перерасчёт с учетом отключенных метрик.
Если поиск дубликатов уже производился и есть эвристически склеенные или признанные недействительными из-за различий в контенте канонические рекомендации (отображаются в аудите), а поиск дубликатов занял значимое для Вас время, то:
Оценить, способны ли эвристические дубликаты и отмененные из-за различий в контенте канонические рекомендации оказать существенное влияние. Если они незначительны, просто отключить поиск дубликатов перед перерасчётами;
Отключить поиск дубликатов и произвести перерасчёты без фильтров, затем уже относительно этих значений делать перерасчёты.
В чём проявляется в интерфейсе склейка эвристических дублей, пагинаций, Canonical и Clean-param
Исходящие ссылки страниц, признанных не основными, переезжают на главную страницу данной структуры (консолидации). Количество исходящих ссылок для таких не основных страниц изменяется на ноль, а цвет становится оранжевым.
Главная страница структуры получит ссылки приклеиваемых к ней страниц, однако это верно только для пагинаций или парсинга по правилам yandexbot: в случае парсинга под googlebot неканонические страницы не передают никаких исходящих с них ссылок, однако все дубликаты проводят статический вес входящих на них самих ссылок.
В итоге мы получим главную страницу консолидации, которая собрала в себе входящие сигналы и статический вес других страниц структуры.
В отличие от исходящих, нормальные входящие ссылки остаются для удобства даже на неканонических страницах, однако количество может измениться и стать также оранжевым, если входящие ссылки перемещены из-за этой или других консолидаций, а также в следствие ручных фильтров.
При вызове окна с деталями, входящие на такую страницу ссылки будут в подразделе, который будет показывать из-за чего удалена или перемещена входящая ссылка. У неё не будет показателей входящего веса. Главная страница консолидации пришлет ответ, если статический вес теперь идёт через неё и будет показывать, сколько этого веса было передано.
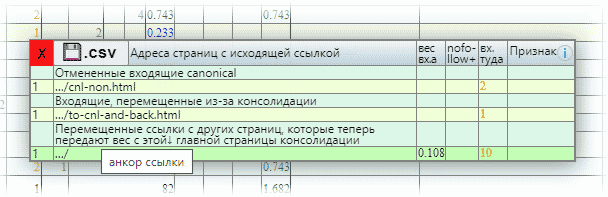
Вот так может выглядеть окно при нажатии на цифровое значение столбца входящих ссылок:
На иллюстрации также видно, что при наведении на строку, появляется всплывающее окно с анкором ссылки. Анкоры также показываются в отдельном столбце при выгрузках входящих ссылок в CSV.
Во всех случаях статический вес входящих ссылок перетекает на каноническую страницу или главную страницу пагинации. Не основные страницы структур собственного веса больше не имеют и не задерживают. Ссылки при склейке не дублируются: учитывается одна исходящая ссылка в пределах структуры при расчёте статического веса. Ссылки между страницами консолидации (перекрёстные ссылки внутри структуры) также перестают существовать. Значения с количеством ссылок в таблице кликабельны и там можно увидеть с разделением на подразделы приклеенные, удаленные или перемещенные ссылки данной страницы. К названиям многих подразделов в окнах с деталями есть всплывающие подсказки.
Автор статьи:
Алексеев Святославfacebook.com/dux.viator SEO-специалист, Web-программист, разработчик SEO-софта и Browser Extensions
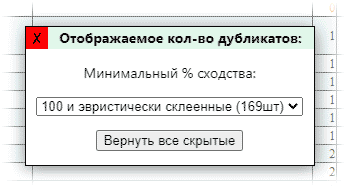 В заголовке ⚙Дубли на грани есть кнопка в виде ⚙, нажатие на которую откроет окно, где можно отсечь дубликаты по минимальному проценту сходства. Здесь также можно просмотреть количество дубликатов с определенным процентом. Выберите 100% и в таблице останутся только полные копии, такие как технические дубли страниц с уникальными адресами и крайне малым различием в контенте, а также те, что были склеены как эвристические дубликаты. Кнопка позволит показать все дубли по умолчанию, включая скрытые инструментом в следующем пункте. Если фильтр затрагивает значение в таблице, оно станет оранжевым.
В заголовке ⚙Дубли на грани есть кнопка в виде ⚙, нажатие на которую откроет окно, где можно отсечь дубликаты по минимальному проценту сходства. Здесь также можно просмотреть количество дубликатов с определенным процентом. Выберите 100% и в таблице останутся только полные копии, такие как технические дубли страниц с уникальными адресами и крайне малым различием в контенте, а также те, что были склеены как эвристические дубликаты. Кнопка позволит показать все дубли по умолчанию, включая скрытые инструментом в следующем пункте. Если фильтр затрагивает значение в таблице, оно станет оранжевым.