Бесплатно оцените, насколько эффективно дополняют аспекты текста страницы общий смысл сайта, т.е. каким количеством дополненной ценности обладает каждый документ. Алгоритм в составе парсера LinksTamed извлекает суть из текста каждой страницы и назначает им баллы, позволяя увидеть страницы, у которых есть неоспоримые проблемы с качеством контента.
Оценка отражает концентрацию дополненного смысла в тексте, потенциальные злоупотребления нивелируются, при этом длина текста влияет на метрику минимально. Так получается «Качество акцента», которое не является метрикой поисковых систем напрямую, но крайне полезно для быстрого поиска проблем с качеством тестов внутри сайта, способных вызвать наложение Thin Content подобных фильтров.
Всё что остается сделать с документом имеющим низкий балл — оценить возможность насытить его текст, описание к картинкам и заголовки терминами и словами-спутниками темы, возможно, слов из уточняющих поисковых запросов. Эти слова будут свойственны документам с других сайтов в выдаче поисковой системы по запросам, на которые должна отвечать данная страница и отражать её УТП (уникальное торговое предложение/отличие). Однако, если семантика конкурентов не проработана, нужно более детально смотреть в сторону уточняющих поисковых запросов и гипонимов в тезаурусе. В некоторых случаях могут помочь с деталями чаты нейронных сетей. При этом, разумеется, слова должны иметь дополненную ценность для пользователя и отвечать интенту его запроса, а потенциальные участки текста, которые могут попасть в сниппет поисковой системы по основному или уточняющему запросу, должны положительно сказываться на целевом действии. Акцентируя внимание именно на запросе (так называемом ключе или ключах) страницы Вы увеличите долю слов, которые встречаются на как можно меньшем количестве не связанных с темой страницы документах (или в меньшем количестве, т.е. с меньшим акцентом). Упрощая, именно это улучшит балл, однако применение редких терминов должно быть типичным для данного запроса, поэтому суещственное влияние на метрику оказывают также термины, которые свойственны не одной этой странице, а той или иной небольшой группе проанализирированных документов, а не просто встречаются только на одной этой странице. Таким образом, метрика отражает закономерности в оценке текста из более сложных алгоритмов, которые используют поисковые системы, что и определяет её ценность.
Как работать с метрикой «Качество акцента»
Запустите обычный парсинг в LinksTamed и после окончания расчетов просто изучите страницы с наиболее низким показателем в столбце качество акцента итоговой таблицы. Это БЕСПЛАТНО. Если тема раскрыта поверхностно, показатель будет низким. В любом случае стоит обратить внимание на 10% документов с самым низким баллом из общего числа документов, где тексты с малым количеством слов и низкой оценкой требуют дописания текста, а самые длинные тексты с низкой оценкой требуют работ по их улучшению (устранения так называемой «воды»). Также стоит изучить несколько страниц с самым высоким баллом, желательно не категорий, а статей, на предмет рациональности раскрытия контекстов. В остальных случаях высокие показатели не несут важной информации. Вы можете вычислить интересующие вас показатели с помощью формул и сортировки после выгрузки данных в файл CSV.
Наиболее важные моменты для работы с метрикой оценки качества акцента текста:
Показатель не подлежит сравнениям с другими сайтами и после больших изменений на сайте, возможно только относительное сравнение в пределах одного парсинга с документами с одинаковым шаблоном;
На практике встречаются значения от 8 до 98. Значения, которые можно считать нормальными, могут отличаться на сайтах в разы;
Точность оценки будет зависеть от количества страниц с текстом на сайте, их должно быть не менее 50-ти для сравнений с приемлемой точностью;
Качество +-2 балла не говорит об очевидном преимуществе одной из страниц;
В отличие от эвристического поиска дубликатов, ценность шаблонных фрагментов, которые есть на 15-79 страницах не снижается, удаляются лишь фрагменты, которые есть хотя бы на 80-ти страницах. Обратите внимание, что ручное удаление блоков на стадии парсинга с помощью методов ==ignore== или ==nottext== модуля Web Scraping может помочь повысить чувствительность алгоритма к оставшемуся контенту нужным вам образом;
Слишком высокий показатель может указывать на инородность контента, отсутствие шаблона, перечисление каких-то редких наименований в очень большом количестве. Косвенно такие страницы могут требовать чуть большего усиления, так как на сайте может недоставать релевантных страниц для усиления сигналов этого документа;
Низкий балл в рамках какого-то раздела может указывать на угрозу обесценивания описаний в глазах просмотревшего несколько подобных однотипных страниц пользователя;
Текст сгенерированный нейронными сетями отличается бедным словарным запасом, поэтому метрика хорошо работает с этим негативным признаком;
Большое количество слов в анкорах, относительно слов в простом тексте, может снизить оценку на 1-2 балла;
Не пытайтесь улучшить оценку, вставляя не уместные для интента пользователя редкие слова, так как им нужен обстоятельный контекст, а в таком случае отступления, не подпадающие под интент, не пойдут ранжированию документа в ПС на пользу. Про насыщение текста просто ключевыми словами можно вообще не говорить. Вы должны понимать, что качество акцента никоим образом не защищено от искусственных манипуляций и лишь указывает на проблемы, требующие уверенного подхода к их устранению.
1.1. Принцип работы метрики «Качество акцента»
Алгоритм призван ответить современным вызовам в области технологий оценки качества текстов, помогая определить один из основополагающих спутников его смысловой ценности — насколько насыщен деталями текст и дополняет ли выделенная из его акцента суть ценность сайта в целом. Иными словами, метрика помогает обратить внимание на документы, в которые не помешает добавить слова-спутники свойственные данной теме (поисковому запросу) (например, на основе эталонного корпуса документов по запросу, по которому должна ранжироваться данная страница с низким баллом), но, разумеется, в рамках интента пользователя.
Чтобы извлечь из метрики максимальную выгоду, важно знать, как она работает:
LinksTamed анализирует каждую словоформу на сайте и считает на скольких страницах упомянуто каждая из них. Учитывается общее количество текстового контента на странице, включая некоторые мета-теги (но уже без минус-слов, удаленных по спискам на странице ПАРАМЕТРЫ). После парсинга создаётся индекс рейтинга, где каждому слову назначается его локальный (внутренний) вес на основе частоты употребления на сайте: слова, которые встречаются редко, получают большую ценность, а популярные — меньшую, при этом вес редких слов преуменьшается по экспоненте. Самые лёгкие минус-слова в языке из списка в настройках просто игнорируются по настраиваемым на странице ПАРАМЕТРЫ спискам для английского, русского и украинского языков. Для этих же языков некоторые слова имеют особый пониженный вес по словарям (увидеть в интерфейсе и изменить их нельзя).
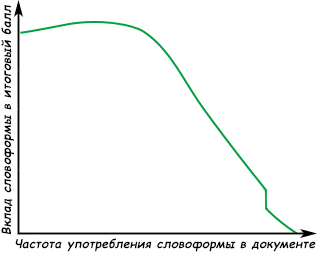
Пик графика показывает, что наиболее влияние оказывают редко встречаемые слова на сайте, при этом, если они употребляются на странице мало или, наоборот, чрезмерное количество раз - их влияние на итоговую оценку снижается. Ступенька в конце графика показывает отсутствие влияния на вклад удалённых минус-слов, которые чаще встречаются среди именно часто употребляемых на странице словоформ.
Далее для каждой страницы считается сумма весов: LinksTamed высчитывает средние показатели частотности словоформ в пределах документа, сортирует их по частоте и частично обесценивает самые популярные и редкие словоформы, выделяя таким образом суть текста. Это опирается на стойкую закономерность распределения частот для естественного языка (закон Ципфа) с рационально выверенной силой коррекции злоупотреблений, которая близка по пропорциям к стойкой закономерности по принципу Парето, дополнительно обработанную локальными весами слов сайта.
Таким образом, частично нивелируются попытки автора акцентировать внимание на ключевых словах, снижается влияние синонимов, опечаток и тому подобного, позволяя выделить эссенцию смысла документа. Всё это делится на общее количество индексируемых словоформ в теле документа. Так мы получили показатель качества уникального акцента не привязанного к количеству слов на странице. Однако, количество оригинального контента всё же влияет — чем меньше оригинального текста, тем больше доля некоторых не удаленных алгоритмом шаблонных элементов и их влияние в сторону снижения балла (пусть они и влияют мало, потому что часто встречаются на сайте).
2.2. Более точное использование метрики качества текста
Теперь можно заметить, что более точной методикой является поиск страницы с самым низким показателем среди страниц какого-то раздела, так как чем больше страниц в категории, тем меньший рейтинг они могут иметь в виду того, что их общая семантика будет употребляться чаще в пределах этого семантического кокона. И наоборот, если в другом разделе меньше карточек — вес их общего отличия будет больше. В любом случае крайние показатели в таблице всегда обратят Ваше внимание на проблемные страницы, но для более точного поиска плохих страниц определённой категории следует сделать сортировку по URL, производя поиск страниц с самыми плохими показателями в пределах радела или общего пути. Для удобства этой практики сделайте выгрузку в CSV через кнопку в интерфейсе LinksTamed, а затем отсортируйте значения в вашей программе для таблиц, такой как Excel или OpenOffice Calc.
2. Релевантность заголовкам и Meta Description
Узнайте, имеются ли в текстовом контенте документа ценные слова из заголовков страницы и ключевых атрибутов, а также оцените их повторяемость по бальной системе от 0 до 10.
Проверка релевантности будет полезна SEO-специалистам, Веб-мастерам и владельцам сайтов для быстрой оценки грубых недочетов в семантике на всех страниц сайта.
2.1. Наличие текста из TITLE, H1 и Description
После краулинга производится проверка на наличие слов в тексте, которые есть в следующих тегах и атрибутах:
TITLE-заголовка страницы;
MetaDescription;
Первого заголовка H1 на странице;
Слов из TITLE-заголовка в описательных атрибутах ALT изображений (уточнения в отдельном подразделе).
Данные выводятся в 8 столбцов в итоговой таблице на главной странице краулера LinksTamed и скрыты по умолчанию. Это 4 пары столбцов: балл релевантности (зависит от того, есть ли все слова из тега, а также в точной или только какой-то другой словоформе) и его расшифровка, которая содержит набор ценных слов, избранных алгоритмом парсера, а также значки подсказки: надйенно ли это слово и если да, то в каком виде (точная словоформа или другая, в тексте или в ссылке). Подробнее о баллах чуть ниже.
Сделать видимыми столбцы можно нажав кнопку Релевантность ▶ в шапке итоговой таблицы.
Ключевые детали работы алгоритма:
При анализе учитываются слова в тексте ВНЕ вышеуказанных в списке тегов и атрибутов, а именно:
вне TITLE-заголовка, MetaDescription (кроме проверки релевантности для TITLE-заголовка) и первого H1 на странице;
Для H1 поиск начинается только в тексте после этого заголовка, т.е. далее по HTML-коду (а точнее DOM-дереву);
Последующие после первого H1 заголовки считаются текстом;
Сравнение идет только по ценным словам, которые избирает алгоритм, минус-слова со страницы ПАРАМЕТРЫ игнорируются;
Алгоритм избирает не более 3-х слов из каждого тега, относительно которого идет поиск в тексте, балл ставится на их основе, а сами эти слова можно посмотреть в поле расшифровки;
Можно исключать шаблонные зоны документов из анализа используются методы ==nottext== или ==ignore== модуля Web scraping, которые исключают текст при парсинге;
Обратите внимание, что пустые значения с баллами (анализ для документа не производился) при прямой и обратной сортировке всегда в конце итоговой таблицы или её раздела\кластера.
Словоформы
Каждое слово может быть найдено в точной словоформе, т.е. так как оно выглядит в теге из которого оно было избрано для дальнейшего поиска в тексте и в другой словоформе данной леммы;
Словоформы определяются для русского и английского языков на основе фирменного самообучающегося алгоритма поддержанного словарями (т.е. часть наиболее популярных слов есть в словаре, а незнакомые слова склоняются на его основе).
Если язык страницы содержит признаки других языков кириллической группы (украинского, белорусского, болгарского, сербского, монгольского кириллического), алгоритм перейдет на упрощенный метод перебора окончаний для русского языка и только для слов длиной от 3 букв, который также поддерживает украинский. Таким образом, для страниц с признаками украинского языка работает поиск словоформ только методом перебора окончаний, что может вызвать больше неточностей. Для других языков все слова являются отдельными, а оценка за повторные совпадения считается только для той же словоформы (если иная не будет засчитана случайно за счет перебора русских, украинских и английских окончаний);
Какие словоформы для русского языка являются общими можно посмотреть на https://dic.academic.ru/contents.nsf/dic_forms, однако некоторые словоформы, если они маловажные, могут быть исключены для предотвращения омонимии или наоборот объединены с другими омоформами, которые маловероятно встречаются в одном документе, но которые невозможно разделить;
Деепричастие прошедшего времени не является частью словоформ в подавляющем числе случаев;
Алгоритм работает со склонением имен собственных лишь по общим правилам, например в случае с фамилией Рыбаков слово будет склоняться по правилам для лексемы рыбак. Некоторые популярные имена собственные добавлены в словари, однако в любом случае алгоритм не делает различий по регистру букв.
2.2. Баллы релевантности текста
Готовая таблица баллов начисляемых за нахождение того или иного текста:
пусто
анализ для страницы не производился
0
баллов
избранные алгоритмом ценные слова ни разу не встречаются в тексте или в теге нет ценных слов
учитывается текст только вне TITLE-заголовка, MetaDescription(кроме проверки релевантности для TITLE-заголовка) и первого H1 на странице (ALT тега IMG учитывается только в рамках своей проверки). Часть текста может быть удалена как шаблонная ссылка или её околоссылочное
2
балла
части слов нет, остальные (не все) лишь в другой словоформе (один и более раз, одной или множества словоформ)
3
балла
части слов нет, но есть одно слово или несколько в точной словоформе по разу, т.е. без повторов в точной или другой словоформе
4
балла
все слова встречаются в тексте, но лишь в других словоформах (один и более раз)
5
баллов
часть слов есть в точной словоформе и некоторые или все из них (этих "не всех") встречаются ещё раз в той же или другой словоформе, однако есть слова, которых нет
6
баллов
все слова есть, но лишь часть слов в точной словоформе, остальные в других словоформах c повторами и без
7
баллов
все слова есть в точной словоформе по разу
8
баллов
все слова есть в точной словоформе и хотя бы одно из них встречается еще раз в тексте в точной или любой другой словоформе
9
баллов
не бывает
10
баллов
все слова есть в точной словоформе и все из них встречаются еще раз в тексте в точной или любой другой словоформе
n*
(число со звездочкой)
все словоформы какого-то слова (или всех) встречается только в ссылках. При этом шаблонные ссылки и их шаблонный околоссылочный текст, которые встречаются на 80-ти и более страницах, не учитываются. Если значение в столбце подсекции релевантности H1 имеет это примечание, значит ссылка где-то после него, а если оценка меньше чем у значения в подсекции релевантности TITLE, значит все эти упоминания "выше по коду" и скорее всего в каком-то меню
Важные моменты:
Внутренний алгоритм LinksTamed удаляющий шаблонные ссылки и шаблонный околоссылочный текст, которые встречаются на 80-ти и более страницах, может удалять этот самый по факту не представляющий ценности околоссылочный текст, что снизит итоговый балл;
Если на страницах есть изменяемые при каждой загрузке страницы блоки текстов или ссылок, они могут затруднить анализ оценки, так как тот или иной участок текста может отсутствовать или наоборот присутствовать, что также может затруднить изучение оценки релевантности.
2.3. Расшифровка релевантности по избранным словам
Справа от выставленного балла находится его расшифровка в виде избранных алгоритмом ценных слов из тега, относительно которого идет сравнение. Каждое избранное слово может быть найдено в точной и другой словоформах (словоформы только для русского, украинского и английского языков), а также быть анкором не удаленной алгоритмом как шаблонной ссылки. Состояния могут сочетаться и для каждого из них, если есть хотя бы одна словоформа лексемы, будет указано кол‑во нахождений в слове:
кол‑во
✔️
слово
слово найдено указанное кол‑во раз в тексте именно в той точной словоформе, в которой она была избрана из тега, относительно которого идет поиск
кол‑во
✔️*
слово
то же самое, но внутри анкора, не удаленного автоматическим алгоритмом исключения шаблонных анокоров с их шаблонным околоссылочным текстом
кол‑во
😐
слово
лексема найдена в другой словоформе отличной от той, в которой она была извлечена из тега. Это может быть одна словоформа или множество разных - все повторы будут засчитаны слева от этого значка в кол‑во. Узнать какие другие словоформы были найдены из таблицы нельзя - избранное слово указывается только в том виде, в котором оно было взято из соответствующего тега
кол‑во
😐*
слово
то же самое, но внутри анкора не удаленного автоматическим алгоритмом исключения шаблонных анокоров с их шаблонным околоссылочным текстом
⛔️
слово
не найдена ни одна словоформа лексемы в тексте и не удаленных автоматическим алгоритмом исключения шаблонных анокоров с их шаблонным околоссылочным текстом
2.4. Проверка релевантности атрибута ALT изображений TITLE-заголовку
LinksTamed также оценивает наличие слов из TITLE-заголовка в описательных атрибутах ALT изображений в теге IMG.
Оценка рассчитываются по тем же правилам что и для текста, за исключением того, что баллы за повторное нахождение слов начисляется только если они в разных ALT, а за соответствие всем словам баллы начисляются только если они в пределах одного атрибута ALT. Таким образом, 7 баллов для одной картинки - это нормально, как и 10 - это значит что два изображения имеют данный набор, но для шаблонных случаев стоит проверить, не одинаковые ли у них по сути альты. Оценка в 7 баллов может вызвать вопросы, когда содержит повторы избранных слов свойственные оценке 8 баллов, нужно понимать, что это повторы из другого изображения имеющего оценку ниже 7-ми. 10 баллов могут быть назначены только если два изображения имеют от 7 и более баллов.
Важные моменты:
При обнаружении низких баллов, проверяйте все изображения, например если это каталог, иначе если устранить проблемы для первого изображения, проблемы с релевантностью последующих изображений не отразятся в оценке;
2.5. Как работает оценка релевантности текста заголовкам
▼
Чтобы оценить релевантность текста TITLE-заголовку страницы, первому H1 и MetaDescription, а также получить оценку лучшего описания в атрибуте ALT тега IMG вне удаленных алгоритмом шаблонных анкоров (включая ссылки-картинки) и их околоссылочных, алгоритм должен отсечь те слова, которые вероятнее всего не имеют ценности, и поэтому на практике имеют право не встречаться в тексте страницы.
В рамках исследуемого заголовка или MetaDescription LinksTamed берет из него слово, которое встречается реже всего на сайте и то, что встречается на сайте чаще всего. Минус-слова со страницы настроек и исключенных вручную для целей оценки релевантности (функционал описан в следующем разделе) игнорируются. После самого редкого слова берется следующее по редкости слово и оценивается, к чему оно ближе по встречаемости - к редкому или самому часто встречаемому. Если ближе к редкому, это слово также будет проверяться на наличие в тексте, иначе набор ценных слов прекращается. Каждое новое слово несколько увеличивает планку и сравнение повторяется до тех пор, пока новые слова подпадают под установленную планку. Далее специальные фильтры проверяют, действительно ли является это слово ценным или его стоит показывать только если с ним проблемы. В итоге в каждом поле
Расшифровка по избранным словам
появится не более трех слов. Понимая этот принцип можно осознать, почему все слова тега нельзя анализировать - некоторые из них просто не имеют никакой ценности и неминуемо лишь приведут к снижению баллов, делая невозможным применение оценки на практике.
После этого производится поиск этих слов в тексте, как в точной словоформе, так и в другой словоформе и на их основе назначаются баллы.
Иногда слова, которые кажутся достаточно распространенными в рамках интернета и не удалены через список на странице ПАРАМЕТРЫ, встречаются на сайте редко в сравнении с другими, поэтому попадают на анализ как ценные слова и это верно, так как осознанно или нет, возникает акцентирование внимания на них. Об исключении таких словоформ в следующем разделе.
2.6. Ручное исключение слов при оценке релевантности
Иногда алгоритм может избрать слова для анализа релевантности, которые не лучшим образом отражают тематику страницы. И хотя некоторые типичные случаи учитываются анализатором, могут понадобиться ручные меры. Причины могут быть разными: от попытки расширить семантику в заголовках словами, которые по идеи должны быть на каждой странице до наоборот упоминания слов характеризующих тему документа слов практически на каждой странице. В обоих случаях возникает проблема с весами слов в алгоритме - не избираются или попадают в избранные не те слова. В этом случае и просто в целях более детального анализа можно исключать слова (будет действовать на все проекты), при этом на место удаленного попадет следующее слово, если оно отвечает критериям.
Важные моменты:
Некоторые слова уже удаляются по списку на странице ПАРАМЕТРЫ.
Исключается слово именно в теге, относительно которого анализируется текст, т.е. фильтр не подойдет для того, чтобы игнорировать те или иные словоформы слова из тега;
Удаление всех слов тега приведет к тому, что слов для анализа найдено не будет и будет назначено 0 баллов (а поле расшифровки будет пустым). В отдельных случаях это можно также трактовать как "в заголовке нет ценных слов".
Для пересчета может понадобиться значительное время, имеет смысл отключить некоторые этапы расчетов (не забудьте их включить перед следующим парсингом).
Если проблема с определением избранных слов связанна с тем, что эти ценные слова встречаются на каждой странице в шаблонном элементе, можно пойти другим путем - исключить его с помощью метода ==nottext== модуля Web Scraping. Это также повысит чувствительность алгоритма поиска дубликатов.
Где найти: текстовое поле для указания слов находится в раскрываемой секции Фильтры расчетов… в разделе Игнорирование слов при оценке релевантности.
2.8. Как убрать из выгрузки или отключить анализ релевантности
Нажать кнопку Релевантность ▶ - как видим итоговую таблицу в интерфейсе программы, так она и попадет в выгрузку.
Этот вид расчетов не занимает много времени, но если вы ходите их отключить, в таблице Этапы работы парсера нужно снять галочку в заголовке этапа
❷ Эвристический поиск неявных дублей, углубленный анализ текста , при этом будут отключены зависимые виды анализа. Возможно включить перерасчеты без повторного парсинга, поставив галочку обратно и нажать на кнопку в раскрываемой секции Фильтры расчетов…
3. Количество заголовков H2
Парсер подсчитывает количество подзаголовков H2 на страницах и выводит их количество рядом со столбцом Всего слов. Многие специалисты считают это полезной метрикой, которая позволяет массово оценивать насыщенность текста разметкой.

, раскрываются кнопкой «Релевантность»")